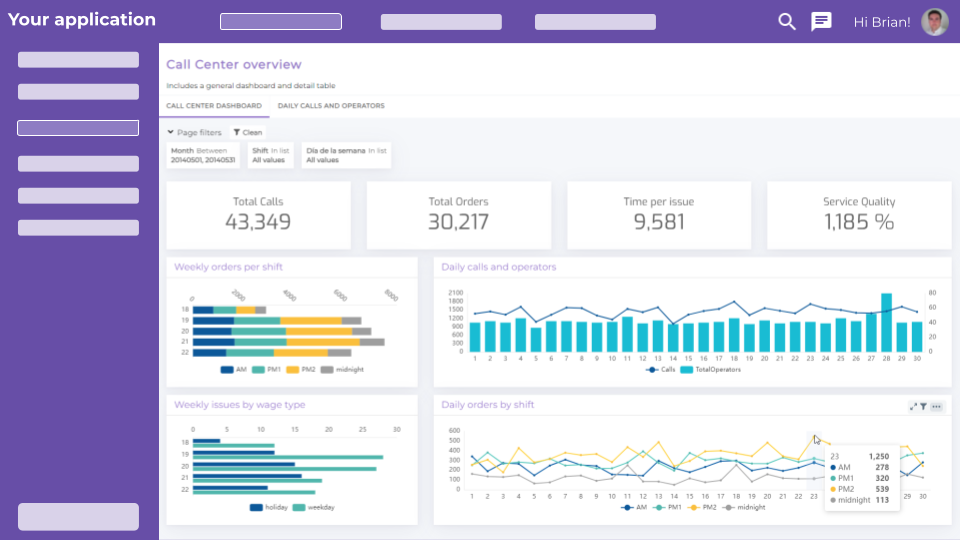
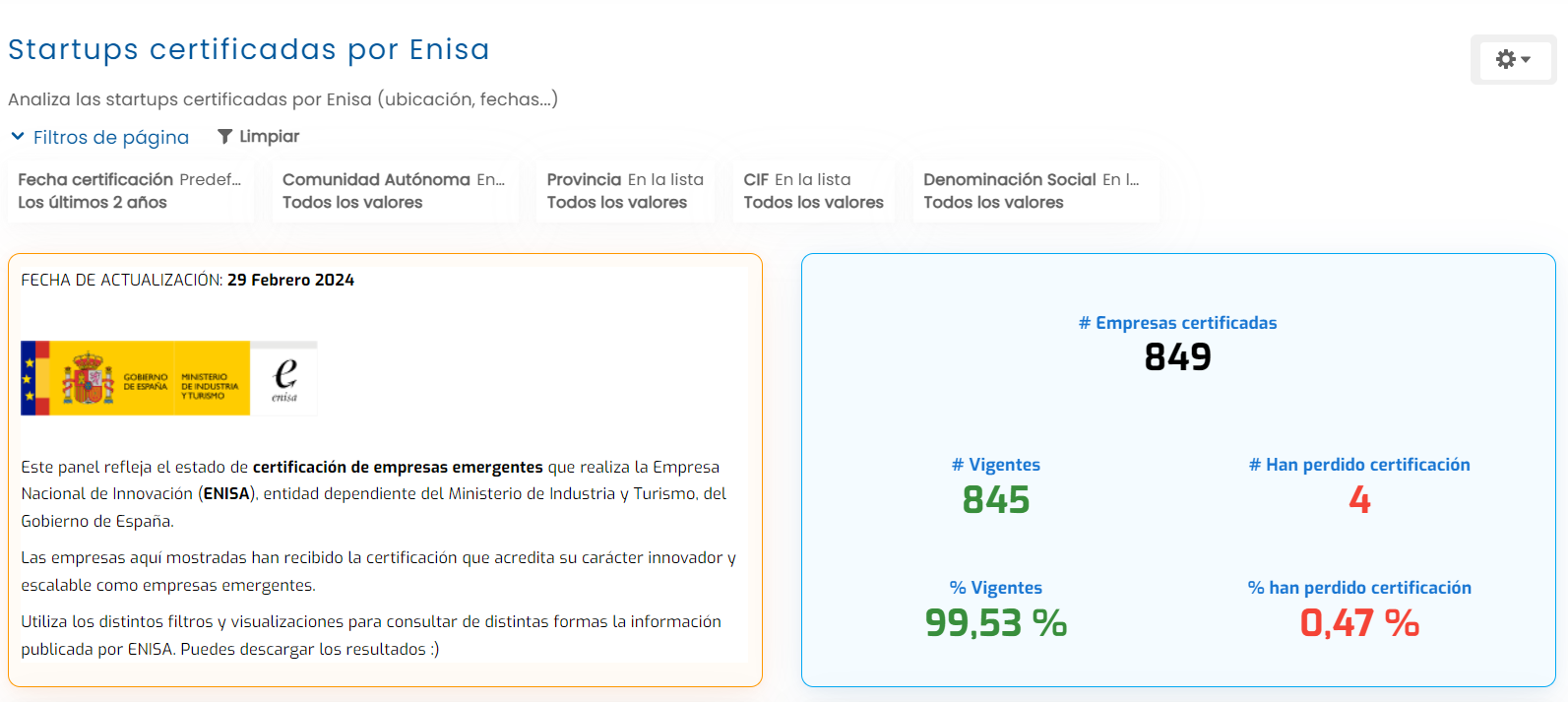
La inteligencia artificial está cambiando la forma en la que las empresas interactúan con sus datos. Hoy ya no hablamos solo de dashboards, informes o cuadros de mando tradicionales. Hablamos de asistentes conversacionales, generación automática de workflows o pipelines de datos así como de visualizaciones, recomendaciones de métricas, resúmenes inteligentes y modelos capaces de responder preguntas en lenguaje natural.

La promesa es potente: acceder antes a la información, reducir la dependencia técnica y hacer que más personas dentro de una organización puedan explorar datos sin necesidad de dominar SQL, herramientas de BI o modelos analíticos complejos.
Pero hay una pregunta que muchas empresas están pasando por alto: ¿qué ocurre si esa inteligencia artificial trabaja sobre datos poco fiables, mal definidos o sin contexto de negocio?
La respuesta es importante. La IA puede acelerar la forma en la que consultamos, interpretamos o visualizamos información, pero no puede convertir por sí sola una base de datos desordenada en una fuente fiable para tomar decisiones. Si los datos son incompletos, inconsistentes, duplicados, mal gobernados o no tienen una definición común, la IA no elimina el problema. En muchos casos, lo amplifica.
Este es el punto en el que aparece la diferencia entre un enfoque AI First y un enfoque Data First.
AI First, mal entendido, significa empezar por la capa visible: el asistente, el generador de dashboards, la interfaz conversacional o la experiencia llamativa. Data First significa empezar por la base: fuentes conectadas, datos preparados, métricas definidas, permisos claros, trazabilidad, gobierno, capa semántica y una forma segura de entregar información a cada usuario.
No se trata de elegir entre IA y datos. Se trata de entender el orden correcto.
Una estrategia moderna de analytics no debería preguntarse únicamente cómo incorporar IA. Debería preguntarse primero si los datos, métricas y modelos sobre los que trabajará esa IA son suficientemente consistentes, comprensibles y gobernados como para generar confianza.
Del dashboard generado por IA al verdadero problema: la confianza
En el artículo anterior analizábamos la diferencia entre dashboards generados por IA y plataformas reales de analytics. La conclusión principal era clara: generar una visualización no equivale a tener una solución analítica preparada para una empresa.
Un dashboard puede parecer correcto y, aun así, estar construido sobre datos incorrectos. Una respuesta generada por IA puede sonar convincente y, aun así, mezclar métricas con definiciones distintas. Un resumen automático puede ser útil y, al mismo tiempo, no estar alineado con los permisos, filtros, modelos de datos o reglas de negocio que necesita cada cliente, equipo o usuario.
Este matiz es especialmente importante en entornos B2B.
Cuando la analítica se usa internamente, un error puede generar confusión, pérdida de tiempo o discusiones entre departamentos. Pero cuando esa analítica se entrega a clientes, partners, franquicias, distribuidores o usuarios externos, el impacto es mayor. Ya no hablamos solo de eficiencia operativa. Hablamos de experiencia de cliente, confianza, retención y percepción de producto.
Una empresa puede crear un dashboard bonito en pocos minutos. También puede conectar una interfaz de IA que permita preguntar por ventas, margen, churn, uso de producto o rendimiento operativo. Pero si detrás no existe una definición común de cada métrica, una lógica consistente para cada segmento, una capa de permisos adecuada y un sistema que explique de dónde viene cada dato, la experiencia será frágil.
El problema no está en que la IA genere respuestas. El problema está en si esas respuestas son verificables, consistentes y seguras.
Por eso, la pregunta no debería ser únicamente: “¿podemos añadir IA a nuestros dashboards?”. La pregunta correcta es: “¿tenemos una base de datos, modelos y métricas suficientemente fiables para que la IA aporte valor?”
Qué significa realmente ser AI First
Ser AI First puede tener mucho sentido si se entiende correctamente. La inteligencia artificial puede reducir fricción, facilitar el autoservicio, ayudar a usuarios no técnicos a explorar información y acelerar tareas que antes requerían más tiempo.
En analytics, esto puede traducirse en interfaces conversacionales, generación automática de visualizaciones, recomendaciones de métricas, detección de patrones, explicaciones en lenguaje natural o asistencia para construir consultas.
En la capa de preparación de datos (Data prep) ser AI First puede ofrecernos la generación de workflows o data pipelines, la generación de datos sintéticos, anonimización de datos y un largo etcétera que enriquezca a una herramienta de ETL tradicional hacia un nivel superior.
Para muchos equipos, esta promesa es especialmente atractiva porque ataca un problema real: el acceso a datos sigue siendo demasiado lento en muchas organizaciones. Los usuarios de negocio dependen de equipos técnicos para obtener informes. Los equipos de data reciben preguntas repetitivas. Los equipos de producto quieren ofrecer analytics dentro de sus aplicaciones, pero no siempre tienen recursos para construir una experiencia completa desde cero.
La IA puede ayudar en todos esos escenarios. Puede hacer que consultar datos sea más natural. Puede reducir la barrera de entrada. Puede convertir una pregunta de negocio en una consulta, una visualización o un resumen. Puede actuar como una interfaz más sencilla entre el usuario y el sistema analítico.
El problema aparece cuando AI First se interpreta como “la IA primero y la arquitectura después”.
En ese escenario, la empresa añade una capa inteligente sobre procesos que siguen siendo manuales, datos que no están preparados, métricas que no tienen owner, modelos de datos que no están documentados y permisos que no están correctamente definidos. El resultado puede parecer moderno, pero sigue siendo frágil.
La IA no sabe por sí sola qué métrica es la oficial, qué dato debe prevalecer cuando hay conflicto entre fuentes, qué cliente puede ver qué información, qué definición de revenue usa la compañía o qué dimensión debe aplicarse en cada caso. Todo eso debe existir antes en la arquitectura de datos, en los procesos, en la capa semántica y en la plataforma que entrega la información.
Un enfoque AI First sin base Data First puede producir una paradoja: la empresa consigue respuestas más rápidas, pero no necesariamente mejores respuestas.
Y en analytics, la velocidad solo es valiosa cuando no compromete la confianza.
Qué significa realmente ser Data First
Ser Data First no significa rechazar la IA. Significa crear las condiciones para que la IA sea útil.
Una empresa Data First empieza por asegurar que los datos están preparados para ser consumidos. Esto implica conectar fuentes, limpiar y transformar información, automatizar procesos recurrentes, definir métricas, establecer reglas de acceso, mantener trazabilidad y entregar la información en un formato comprensible para cada usuario.
En un contexto de BI, embedded analytics o data portals, Data First significa que la visualización final no es una pieza aislada. Es la última capa de un sistema que empieza mucho antes.
Primero están las fuentes de datos: CRM, ERP, producto, operaciones, finanzas, marketing, soporte, bases de datos internas o sistemas externos. Después viene la preparación de datos: extracción, transformación, validación, limpieza, deduplicación y enriquecimiento. Luego aparecen los modelos de datos, las reglas de negocio, la definición de métricas, la capa semántica, los permisos, la experiencia de usuario y por último la entrega final, la capa de visualización de datos.
Solo entonces tiene sentido añadir IA como una capa adicional para explorar, resumir, preguntar o acelerar la interacción con la información.
Data First no es construir más infraestructura por construir. Es crear una base fiable para que cualquier capa de consumo (dashboards, portales, analytics embebido, reporting interno o modelos de IA) funcione de forma consistente.
Dicho de forma sencilla: la IA puede mejorar la experiencia analítica, pero la confianza depende de los datos, de las métricas y del contexto que los conecta con el negocio.
La capa semántica: el puente entre los datos, el BI y la IA
Dentro de una estrategia Data First hay una pieza que cada vez gana más importancia: la semantic layer o capa semántica.
La capa semántica actúa como una capa intermedia entre los datos técnicos y las herramientas que los consumen. Su función es traducir tablas, columnas, relaciones y modelos de datos en conceptos comprensibles y consistentes para el negocio: métricas, dimensiones, entidades, jerarquías, reglas de cálculo y definiciones compartidas.
En otras palabras, la capa semántica ayuda a que conceptos como “ingresos”, “cliente activo”, “churn”, “margen”, “MRR”, “conversi�ón”, “uso de producto” o “ticket medio” tengan una definición común y reutilizable.
Esto es muy útil para herramientas de BI, porque evita que cada dashboard, equipo o analista reconstruya las métricas a su manera. Pero también es especialmente importante para los modelos de IA.
Cuando un usuario pregunta a un asistente: “¿cuáles son mis clientes con mayor riesgo de abandono?” o “¿cómo han evolucionado los ingresos recurrentes este trimestre?”, el modelo necesita algo más que acceso a una base de datos. Necesita contexto. Necesita saber qué significa cada métrica, qué relaciones existen entre entidades, qué filtros deben aplicarse, qué dimensiones son relevantes y qué reglas de negocio no deben ignorarse.
Sin una capa semántica, la IA puede interpretar los datos de forma ambigua. Puede seleccionar una tabla incorrecta, usar una definición equivocada, mezclar conceptos o responder con una lógica que no coincide con la que usa la organización. Con una capa semántica bien definida, tanto las herramientas de BI como los modelos de IA pueden operar sobre una misma base de significado.
Esto no elimina por completo la necesidad de validación, gobierno o supervisión, pero reduce una de las principales fuentes de riesgo: la inconsistencia semántica.
Por eso, en la era de la IA, la capa semántica deja de ser solo una buena práctica de BI. Se convierte en una infraestructura crítica para que los sistemas inteligentes puedan interpretar datos con contexto, consistencia y garantías.
Una estrategia Data First no debería limitarse a almacenar y visualizar datos. Debería definir también el lenguaje común con el que la organización entiende esos datos.
AI First vs Data First: comparación práctica
La diferencia entre AI First y Data First no está en usar o no usar inteligencia artificial. La diferencia está en qué se considera el fundamento del sistema.
En un enfoque AI First mal planteado, la prioridad es generar respuestas rápido. En un enfoque Data First, la prioridad es generar respuestas fiables. En el primero, la capa visible puede avanzar más rápido que la base. En el segundo, la base permite que cualquier capa visible (dashboards, portales, embedded analytics o IA) funcione de forma consistente.
| Dimensión | AI First mal entendido | Data First |
|---|---|---|
| Punto de partida | Interfaz de IA | Datos, modelos, métricas y contexto |
| Prioridad | Generar respuestas rápido | Generar respuestas fiables |
| Riesgo principal | Respuestas inconsistentes, falsa confianza o interpretación ambigua | Mayor trabajo inicial de preparación y gobierno |
| Relación con las métricas | Las métricas se definen, documentan y reutilizan de forma consistente | Las métricas se definen, documentan y reutilizan de forma consistente |
| Capa semántica | Puede no existir o estar implícita en cada herramienta | Actúa como lenguaje común entre datos, BI e IA |
| Escalabilidad | Limitada si los datos no están gobernados ni preparados para crecer | Alta si existe una arquitectura sólida |
| Mantenimiento | Difícil si cada output se genera de forma aislada | Gestionable si métricas, modelos, permisos y semántica están centralizados |
| Experiencia de usuario | Atractiva, pero potencialmente frágil | Consistente, segura y confiable |
| Encaje B2B | Riesgoso en escenarios multi-cliente si no hay permisos y gobierno | Adecuado para reporting, portales y analytics embebido |
| Resultado | Insights rápidos, pero no siempre accionables | Decisiones más confiables y repetibles |
Esto tiene implicaciones directas para empresas SaaS, ISVs y organizaciones que entregan reporting a clientes.
Si cada cliente ve datos con reglas distintas, si las métricas no tienen una definición común, si la capa semántica no existe o si los permisos no están bien resueltos, añadir IA no soluciona el problema. Puede hacerlo más visible. Y en algunos casos, más difícil de controlar.
Por el contrario, cuando existe una base Data First, la IA puede convertirse en una ventaja real: ayuda a consultar mejor, detectar patrones, explicar información y acelerar el acceso a insights sin comprometer la confianza.
Por qué este debate importa especialmente en empresas SaaS e ISVs
Para una empresa SaaS o un ISV (Independent Software Vendor o Proveedor Independiente de Software), la analítica no es solo reporting. Muchas veces forma parte del propio producto.
Los clientes esperan ver métricas claras, dashboards útiles y datos actualizados dentro de su experiencia habitual. No quieren exportar información, pedir informes manuales o depender del equipo de soporte para entender qué está pasando. Quieren autoservicio, claridad y confianza.
En este contexto, un enfoque AI First superficial puede ser peligroso. Una interfaz conversacional puede parecer innovadora, pero si detrás no existe una arquitectura multi-cliente, control de acceso, trazabilidad, capa semántica y definiciones comunes, la experiencia puede romperse rápidamente.
Pensemos en una compañía SaaS que ofrece métricas de rendimiento a sus clientes. Si cada cliente accede a un portal con datos propios, el sistema debe garantizar que nadie ve información que no le corresponde. También debe asegurar que los KPIs tienen una definición consistente, que los filtros se aplican correctamente y que las respuestas generadas por IA respetan el mismo modelo de permisos que los dashboards oficiales.
En este tipo de escenario, el problema no es solo técnico. Es de producto y de confianza.
Un enfoque Data First permite construir analítica como una capacidad de producto. No solo como una pantalla más, sino como una parte integrada de la propuesta de valor: dashboards embebidos, portales de datos, reporting white-label, permisos por usuario o cliente, métricas consistentes y una experiencia alineada con el contexto de cada usuario.
La IA puede entrar después para mejorar la exploración, pero no debería sustituir la base.
De hecho, cuanto más estratégica sea la analítica dentro del producto, más importante será que la IA opere sobre un sistema preparado. No basta con que el modelo responda. Debe responder con los datos correctos, el contexto correcto, las métricas correctas y las restricciones correctas.
El problema que aparece después: mantenimiento, cambios y escalabilidad
Otra limitación habitual de un enfoque AI First es que suele resolver mejor el problema inicial que el problema continuo.

La IA puede ayudar a generar un primer dashboard, una primera consulta, un primer pipeline o una primera visualizaci�ón. Puede acelerar el prototipo y reducir el tiempo necesario para llegar a una primera versión. Pero una solución analítica empresarial no termina cuando se genera por primera vez. Empieza precisamente ahí.
Después llegan los cambios funcionales, los nuevos requisitos de negocio, las modificaciones en las fuentes de datos, las nuevas métricas, los cambios en la lógica de cálculo, las necesidades de segmentación, las nuevas reglas de permisos, los ajustes de seguridad, las auditorías, las optimizaciones de rendimiento y los escenarios de escala.
¿Qué ocurre si cambia la definición de una métrica crítica? ¿Quién actualiza todos los dashboards, modelos y respuestas que dependen de ella? ¿Qué pasa si un cliente necesita una nueva regla de acceso? ¿Cómo se asegura que esa regla se aplica igual en un dashboard, en un portal de datos y en una consulta realizada mediante IA? ¿Qué sucede si la plataforma pasa de tener 100 usuarios consumiendo información a tener 1.000, 10.000 o más?
Estos son problemas menos visibles que la generación inicial, pero mucho más importantes para una empresa. La IA puede ser muy útil para crear, sugerir o acelerar. Pero mantener una solución estable, segura, gobernada y escalable requiere arquitectura, procesos, ownership y una plataforma preparada para operar en el tiempo.
En analítica empresarial, la dificultad no está solo en crear una respuesta. Está en garantizar que esa respuesta siga siendo correcta cuando cambian los datos, las reglas de negocio, los usuarios, los permisos o el volumen de consumo.
Por eso, el enfoque Data First no es simplemente una forma más ordenada de empezar. Es una forma más robusta de mantener. Cuando existen modelos definidos, métricas gobernadas, capa semántica, trazabilidad, permisos y una arquitectura de entrega, los cambios pueden gestionarse de forma centralizada y consistente. Cuando todo depende de artefactos generados de forma aislada, el mantenimiento se vuelve más frágil.
Una solución analítica real debe poder evolucionar. Debe soportar nuevos requisitos sin romper lo existente. Debe permitir modificar una métrica sin generar versiones contradictorias. Debe escalar a más usuarios sin comprometer rendimiento ni seguridad. Y debe hacerlo con responsabilidades claras, no como una colección de outputs generados puntualmente.
Esta es una de las grandes diferencias entre “generar analytics” y “operar una plataforma de analytics”. La primera parte puede parecer rápida. La segunda es la que determina si el sistema perdura.
El error habitual: confundir velocidad con fiabilidad
Uno de los grandes atractivos de la IA es la velocidad. Permite generar respuestas en segundos, crear visualizaciones rápidamente y reducir la barrera de entrada para usuarios no técnicos.
Pero en analítica empresarial, velocidad y fiabilidad no son lo mismo.

Una respuesta rápida puede estar mal contextualizada. Un dashboard generado automáticamente puede usar una métrica incorrecta. Una recomendación puede parecer razonable, pero no estar alineada con la lógica de negocio. Y cuando esto ocurre, el coste no es solo técnico. Es organizativo y comercial.
En equipos internos, esto genera discusiones sobre qué número es correcto. En clientes, genera pérdida de confianza. En producto, genera fricción. En ventas, puede complicar una demo o una renovación. En operaciones, puede llevar a decisiones equivocadas.
La capa semántica ayuda precisamente a reducir este riesgo. Si las métricas, dimensiones, jerarquías y reglas de negocio están definidas en una capa común, las herramientas de BI y los sistemas de IA no tienen que interpretar desde cero cada consulta. Trabajan sobre un marco compartido.
Esto no significa que todo quede resuelto automáticamente. Sigue siendo necesario gobernar el dato, supervisar los modelos, validar respuestas y mantener una arquitectura segura. Pero sí significa que la organización reduce la probabilidad de que dos herramientas distintas ofrezcan respuestas diferentes para la misma pregunta.
Por eso, las empresas que quieran incorporar IA a su analítica deberían hacerse una pregunta previa: ¿podemos explicar de dónde sale cada dato, qué significa cada métrica, quién la define y quién debería verla?
Si la respuesta es no, el problema no está en la IA. Está en la base.
Cómo combinar IA y Data First de forma correcta
La combinación correcta no es IA contra datos. Es IA sobre datos fiables.
El primer paso es ordenar las fuentes y procesos de preparación. Esto implica reducir tareas manuales, automatizar transformaciones, evitar duplicidades y asegurar que los datos llegan en condiciones al sistema analítico.
El segundo paso es definir modelos de datos claros. Las relaciones entre entidades, tablas, clientes, productos, eventos, cuentas o transacciones deben estar estructuradas de forma que puedan ser entendidas y reutilizadas por distintas herramientas.
El tercer paso es definir métricas y ownership. Cada KPI importante debería tener una definición clara, un responsable y una lógica consistente. Si ventas, producto y operaciones usan definiciones distintas para la misma métrica, cualquier capa de BI o IA heredará esa ambigüedad.
El cuarto paso es construir una capa semántica. Esta capa añade contexto a los modelos y métricas, traduce la complejidad técnica a lenguaje de negocio y permite que tanto las herramientas de BI como los modelos de IA interpreten los datos de forma consistente. No se trata solo de nombrar métricas, sino de definir su lógica, sus relaciones, sus dimensiones y sus reglas de uso.
El quinto paso es aplicar gobierno, seguridad y permisos. Esto es crítico cuando los datos se entregan a clientes, partners o usuarios externos. No todos los usuarios deben ver lo mismo, y no todos los contextos requieren la misma granularidad.
El sexto paso es entregar la analítica en el lugar adecuado: dashboards internos, analytics embebido, portales de datos o reporting white-label. La experiencia importa, pero debe apoyarse en una base sólida.
Solo después tiene sentido incorporar IA como capa de exploración, asistencia o automatización.
La secuencia correcta no es “IA → datos”. Es “datos fiables → modelos consistentes → capa semántica → analítica útil → IA como acelerador”.
Qué debería tener una plataforma de analytics preparada para la era de la IA
Una plataforma de analytics preparada para la era de la IA no debería limitarse a mostrar gráficos. Debería ayudar a construir una base analítica fiable, segura y reutilizable.
Esto implica resolver varios niveles a la vez.
En primer lugar, debe poder conectarse con distintas fuentes de datos y facilitar que la información se prepare antes de llegar al usuario final. Si los datos requieren procesos manuales constantes, hojas de cálculo intermedias o transformaciones no documentadas, la analítica será difícil de escalar.
En segundo lugar, debe permitir crear dashboards claros, reutilizables y adaptados a distintos perfiles de usuario. No todos los usuarios necesitan el mismo nivel de detalle, ni todos interpretan los datos desde el mismo contexto.
En tercer lugar, debe incorporar seguridad y control de acceso. En escenarios multi-cliente, embedded analytics o data portals, esto no es opcional. Es una condición básica para entregar datos a usuarios externos.
En cuarto lugar, debe facilitar consistencia en métricas y modelos. Aquí la capa semántica juega un papel clave, porque ayuda a que distintas herramientas y usuarios trabajen sobre una misma definición de negocio.
Y en quinto lugar, debe estar preparada para que la IA pueda consumir los datos con contexto suficiente. No basta con conectar un modelo a una base de datos. La IA necesita entender qué significan las métricas, qué relaciones existen, qué reglas deben aplicarse y qué límites de acceso tiene cada usuario.
Una checklist práctica para evaluar una plataforma moderna de analytics podría incluir:
-
Conexión con múltiples fuentes de datos.
-
Preparación y transformación de datos.
-
Automatización de procesos recurrentes.
-
Modelos de datos reutilizables.
-
Capa semántica para métricas, dimensiones y contexto de negocio.
-
Dashboards claros y reutilizables.
-
Seguridad por roles, usuarios, clientes o grupos.
-
Capacidad multi-cliente.
-
Opciones de embedded analytics.
-
Portales de datos para usuarios externos.
-
Experiencia white-label.
-
Trazabilidad y consistencia de métricas.
-
Escalabilidad para crecer sin rehacer el sistema.
-
Capacidad de alimentar herramientas de BI y modelos de IA con una base común.
-
Gestión centralizada de cambios en métricas, modelos, permisos y reglas de negocio.
-
Escalabilidad operativa para soportar más usuarios, clientes y casos de uso sin rehacer la arquitectura.
Una plataforma moderna no debería limitarse a visualizar datos. Debería ayudar a prepararlos, gobernarlos, contextualizarlos, entregarlos y convertirlos en decisiones.
Además, debería facilitar el mantenimiento a largo plazo. No basta con crear dashboards o respuestas inteligentes una vez. La plataforma debe permitir evolucionar métricas, adaptar modelos, cambiar permisos, incorporar nuevos usuarios y responder a nuevos requisitos funcionales sin convertir cada cambio en un proyecto técnico desde cero.
El papel de Biuwer en una estrategia Data First
Biuwer encaja en este debate porque su propuesta no se limita a crear dashboards. Su enfoque está en ayudar a las empresas a preparar y entregar datos fiables a clientes y equipos, desde la integración y preparación del dato hasta su consumo en dashboards, analytics embebido y portales de datos.
Para empresas SaaS, ISVs, consultoras, organizaciones multi-cliente o compañías con reporting complejo, esto es especialmente relevante. La analítica no puede depender de informes manuales, desarrollos ad hoc o soluciones poco escalables. Necesita una plataforma que combine experiencia visual, seguridad, autoservicio, escalabilidad y capacidad de entrega.
En ese contexto, la IA puede ser una capa de valor. Pero el valor real empieza antes: en construir una base de datos fiable, gobernada y preparada para ser consumida por las personas adecuadas, en el contexto adecuado.
El enfoque Data First conecta directamente con una visión end-to-end del dato: fuentes, preparación, modelos, métricas, capa semántica, dashboards, analytics embebido, portales de datos y decisiones. Cada capa añade valor, pero también reduce riesgo.
Para un equipo de producto, esto significa poder ofrecer analytics dentro de una aplicación sin construir toda la infraestructura desde cero. Para un equipo de data, significa reducir inconsistencias y facilitar la entrega de información. Para un equipo directivo, significa tomar decisiones con mayor confianza. Para los clientes finales, significa acceder a datos claros, seguros y comprensibles.
La IA no desaparece de esta visión. Al contrario: se vuelve más útil cuando tiene una base fiable sobre la que trabajar.
Conclusión: la IA no sustituye la confianza
La inteligencia artificial va a transformar la forma en la que interactuamos con los datos. Pero no cambia una realidad básica: para tomar buenas decisiones, primero necesitamos datos fiables.
AI First puede crear experiencias llamativas. Data First crea sistemas que escalan.
La mejor estrategia no consiste en elegir entre ambas. Consiste en construir primero una base sólida de datos, modelos, métricas, capa semántica, seguridad, mantenimiento y entrega analítica, y después usar la IA para acelerar el acceso a insights.
Porque en analytics, la pregunta más importante no es si una respuesta se genera rápido.
Es si se puede confiar en ella.
Si tu empresa está construyendo reporting para clientes, analytics embebido o portales de datos, Biuwer puede ayudarte a entregar datos fiables de forma visual, segura y escalable.
FAQs
¿Qué significa AI First?
AI First significa priorizar la inteligencia artificial como capa principal de interacción, automatización o generación de respuestas. En analytics, suele traducirse en dashboards generados automáticamente, consultas en lenguaje natural o asistentes para explorar datos.
¿Qué significa Data First?
Data First significa construir primero una base fiable de datos: calidad, gobierno, trazabilidad, modelos, métricas, seguridad y procesos de preparación. La IA puede añadirse después como una capa de valor sobre esa base.
¿Es mejor AI First o Data First?
No son enfoques excluyentes, pero en analítica empresarial conviene empezar por Data First. Si los datos no son fiables, la IA puede acelerar errores, inconsistencias y decisiones mal fundamentadas.
¿Qué es una capa semántica en analytics?
Una capa semántica es una capa que define métricas, dimensiones, relaciones y reglas de negocio para que distintas herramientas puedan interpretar los datos de forma consistente. Ayuda a que BI e IA trabajen sobre un mismo contexto compartido.
¿Por qué la capa semántica es importante para la IA?
Porque los modelos de IA necesitan contexto para interpretar correctamente los datos. Sin una capa semántica, pueden usar definiciones ambiguas, seleccionar métricas incorrectas o responder con una lógica distinta a la que usa la organización.
¿Puede la IA crear dashboards fiables?
Puede ayudar a generar visualizaciones, consultas o resúmenes, pero la fiabilidad depende de la calidad, estructura, gobierno, contexto semántico y seguridad de los datos sobre los que trabaja.
¿Cómo aplicar una estrategia Data First en analytics?
El primer paso es ordenar fuentes, preparar datos, definir modelos, establecer métricas, construir una capa semántica, aplicar permisos, asegurar trazabilidad y entregar la información mediante dashboards, embedded analytics o data portals adaptados a cada usuario.