El proyecto PREDATA (Preparation and Refinement Environment for DATAspaces) nació con el objetivo de desarrollar una herramienta cloud para la preparación y tratamiento avanzado de datos, orientada a facilitar su conexión e integración posterior con Espacios de Datos.
Tras el trabajo realizado durante el proyecto, PREDATA se presenta como una herramienta funcional que permite construir workflows visuales para transformar datos heterogéneos en datasets más fiables, seguros e interoperables. Este artículo resume los principales resultados obtenidos y forma parte de las actividades de amplia difusión del proyecto, junto con el webinar de presentación, la demostración práctica de la herramienta y los materiales públicos asociados.

El objetivo es compartir con el ecosistema de datos el conocimiento generado durante el proyecto, explicar la necesidad abordada y mostrar cómo PREDATA contribuye a resolver uno de los retos clave para participar en Espacios de Datos: preparar los datos antes de compartirlos.
El contexto: por qué los Espacios de Datos necesitan datos preparados
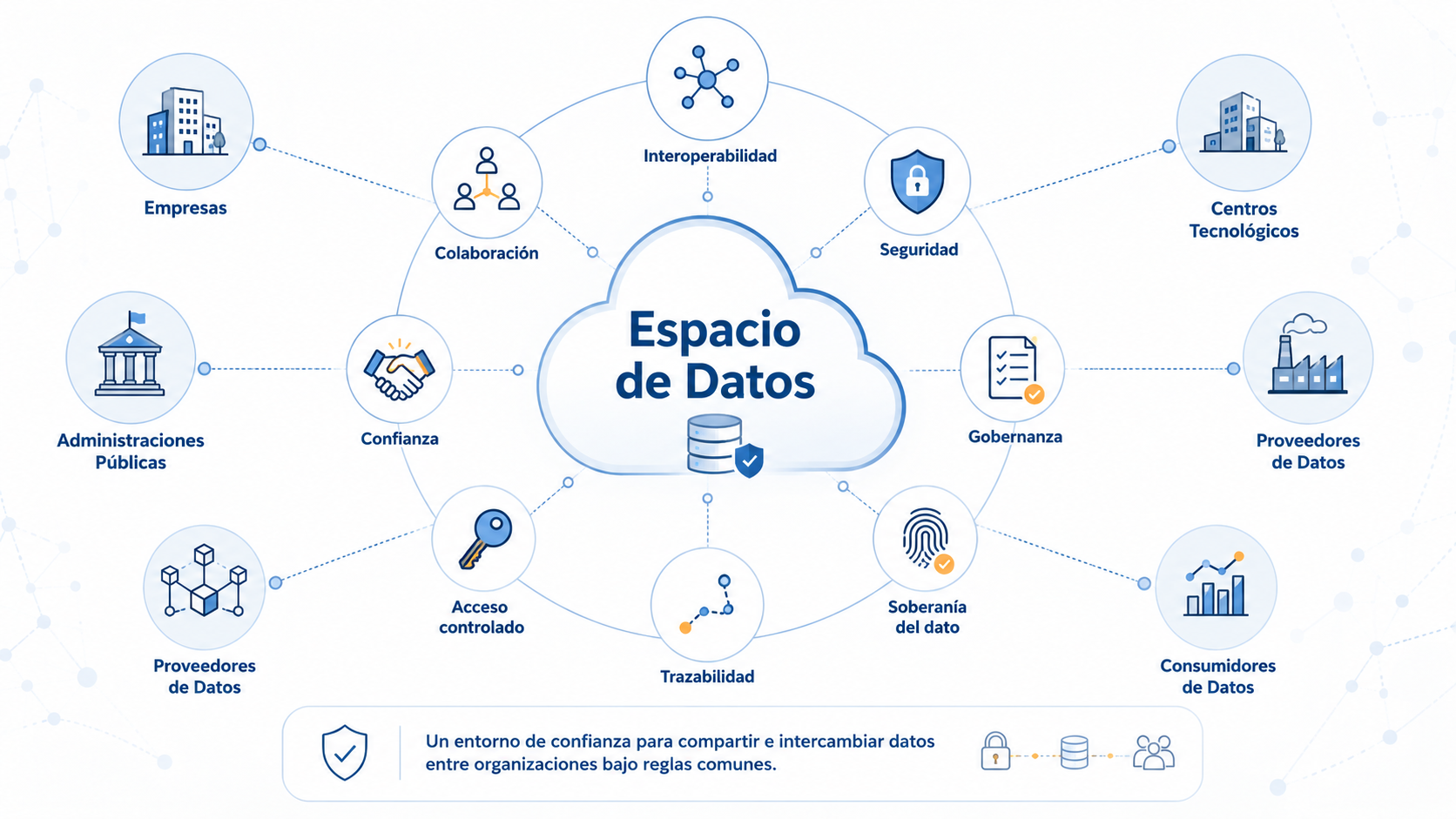
Los Espacios de Datos son entornos de confianza que permiten a diferentes organizaciones compartir, publicar, consumir o intercambiar datos bajo reglas comunes. No son simplemente bases de datos centralizadas, sino ecosistemas donde intervienen participantes, tecnología, gobernanza, seguridad, trazabilidad y control de acceso.
Para que estos ecosistemas funcionen correctamente, no basta con disponer de datos. Los datos deben cumplir unas condiciones mínimas de calidad, estructura, privacidad, interoperabilidad y trazabilidad. Sin esa preparación previa, su reutilización se vuelve más compleja y aumenta el riesgo de errores, incumplimientos normativos o pérdida de confianza entre participantes.
En este contexto, PREDATA se ha desarrollado como una herramienta enfocada precisamente en esa fase previa: el tratamiento y refinamiento de los datos antes de su incorporación a un Espacio de Datos.
""Tener datos no es suficiente. Para compartirlos con garantías, primero hay que prepararlos.
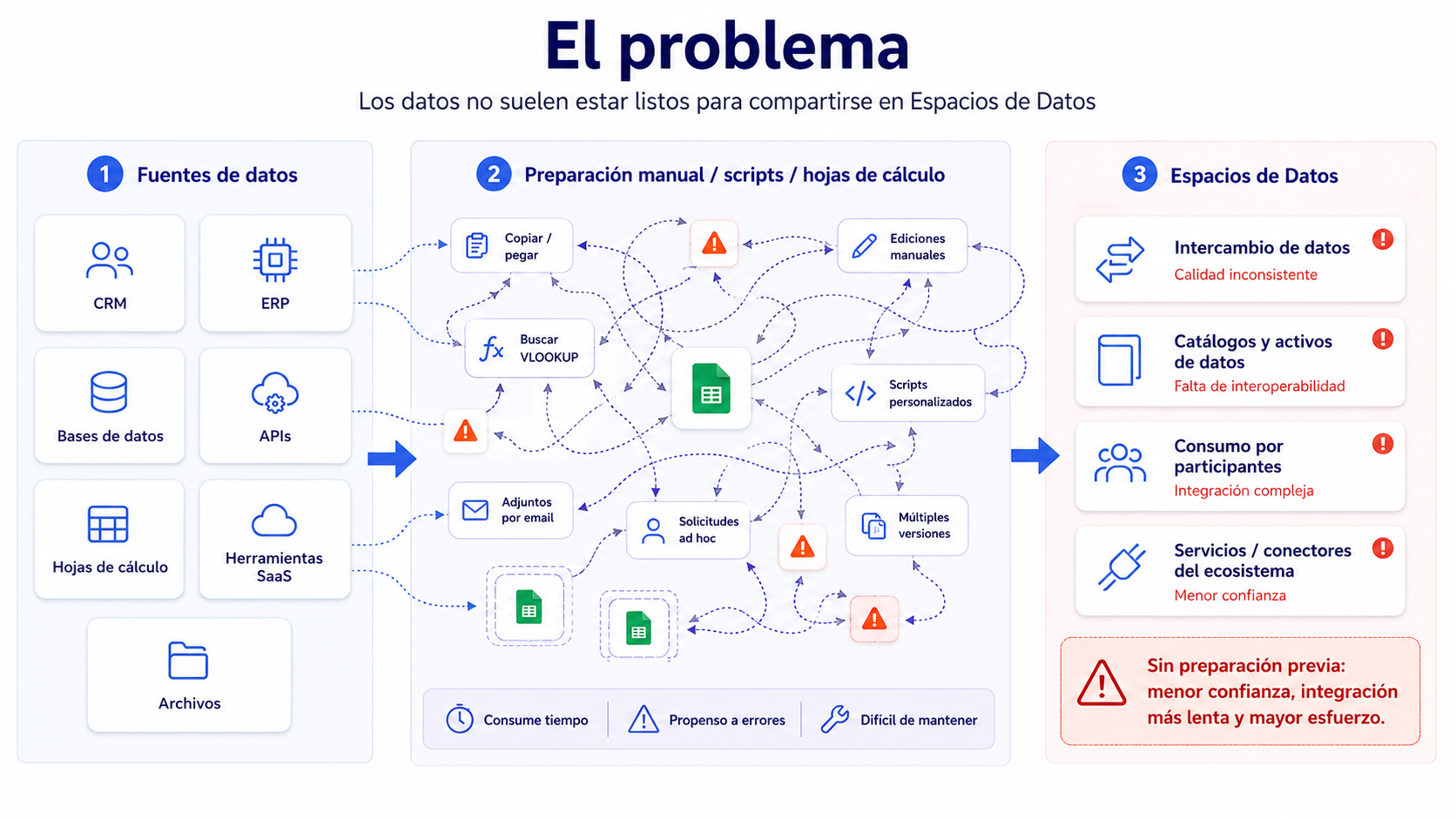
El problema abordado: datos fragmentados, heterogéneos y difíciles de reutilizar
En muchas organizaciones, los datos se encuentran distribuidos en múltiples sistemas: bases de datos internas, ficheros CSV o Excel, APIs, aplicaciones cloud, sensores IoT o repositorios documentales. Además, estos datos pueden presentar diferentes niveles de calidad y estructura.
Entre los retos más habituales se encuentran los formatos no estandarizados, valores incompletos o inconsistentes, duplicidades, información sensible, ausencia de trazabilidad sobre las transformaciones aplicadas o dificultad para exportar datasets en formatos interoperables.
Este problema no es únicamente técnico. Afecta directamente a la confianza, la privacidad, la reutilización del dato y la capacidad de las organizaciones para participar en ecosistemas colaborativos. Por ello, una de las conclusiones clave del proyecto es que la preparación previa del dato debe abordarse como una fase específica, automatizable y trazable dentro del ciclo de vida de los datos.
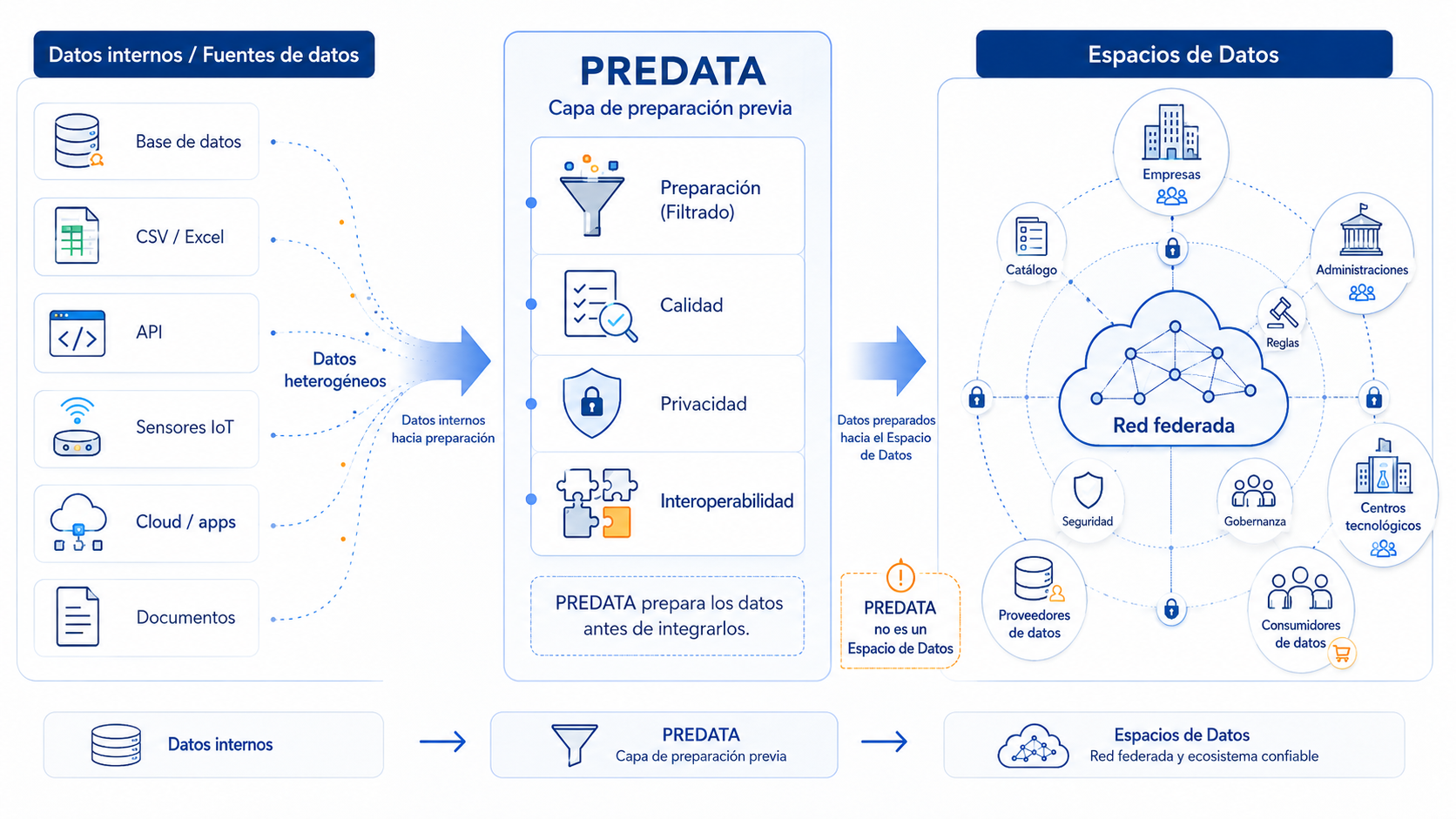
La solución desarrollada: PREDATA como capa previa de preparación del dato
PREDATA se ha desarrollado como una capa previa de preparación del dato. Su objetivo no es sustituir a un Espacio de Datos, sino facilitar que los datos puedan llegar a esos entornos en mejores condiciones de calidad, seguridad e interoperabilidad.
La herramienta permite crear workflows visuales de tratamiento de datos, conectar fuentes heterogéneas, aplicar transformaciones, validar la calidad de los datasets, proteger información sensible y exportar los resultados en formatos estándar.
Desde un punto de vista funcional, PREDATA actúa como un puente entre los sistemas internos de una organización y los entornos donde esos datos pueden compartirse, consumirse o reutilizarse posteriormente.
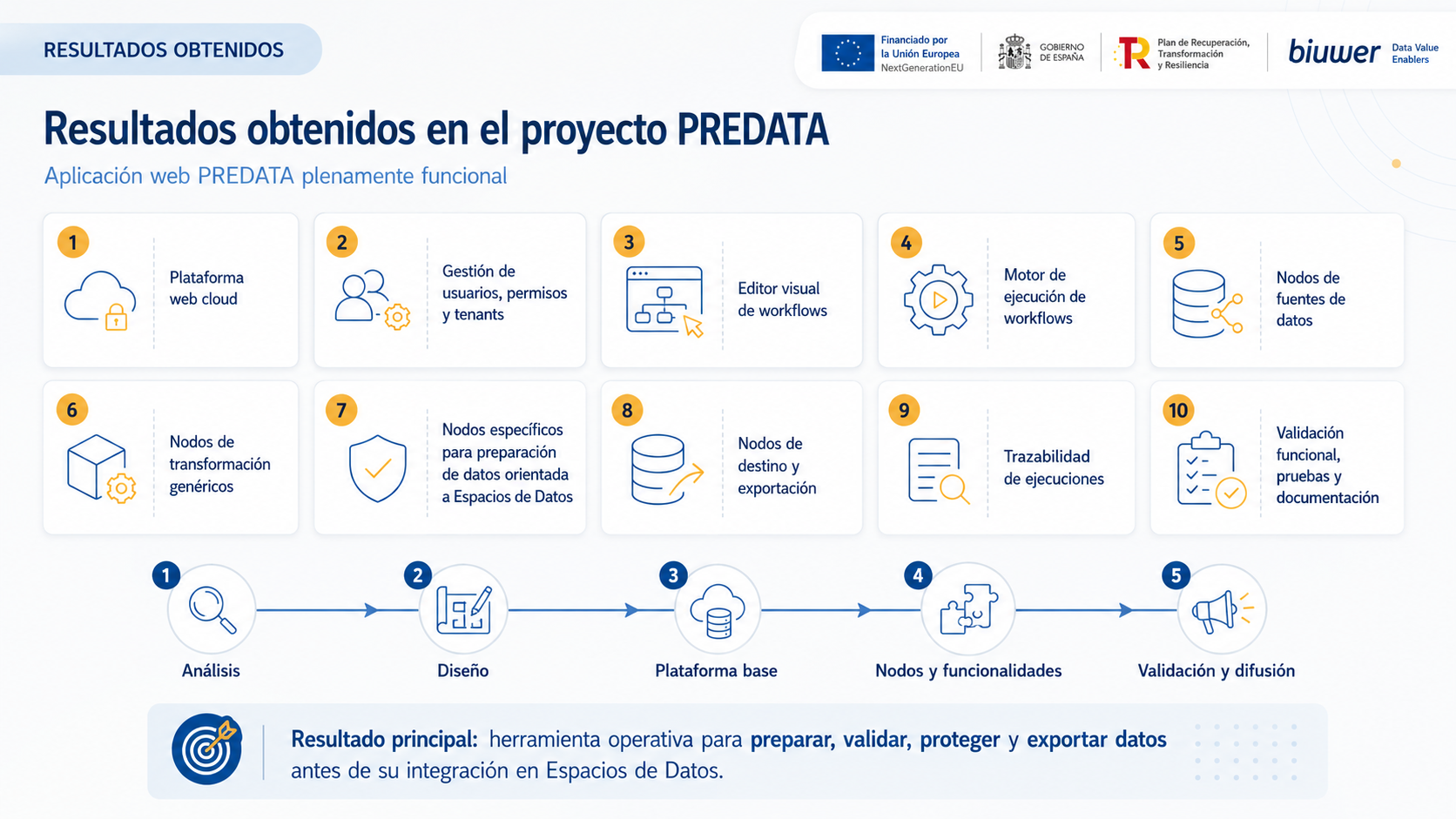
Resultados técnicos obtenidos
Como resultado del proyecto, se ha desarrollado una herramienta funcional que integra los componentes necesarios para diseñar, ejecutar y supervisar procesos de preparación de datos mediante workflows.
Entre los principales resultados obtenidos se encuentran:
- Plataforma web cloud para la gestión de workflows de datos.
- Gestión de usuarios, permisos y tenants.
- Editor visual de workflows basado en nodos configurables.
- Motor de ejecución de workflows.
- Nodos de conexión con fuentes de datos.
- Nodos de transformación genéricos.
- Nodos específicos para la preparación de datos orientada a Espacios de Datos.
- Nodos de destino y exportación.
- Capacidades de trazabilidad y auditoría de ejecuciones.
- Validación funcional, pruebas y documentación de usuario.
El resultado principal es una herramienta operativa para preparar, validar, proteger y exportar datos antes de su integración en Espacios de Datos.
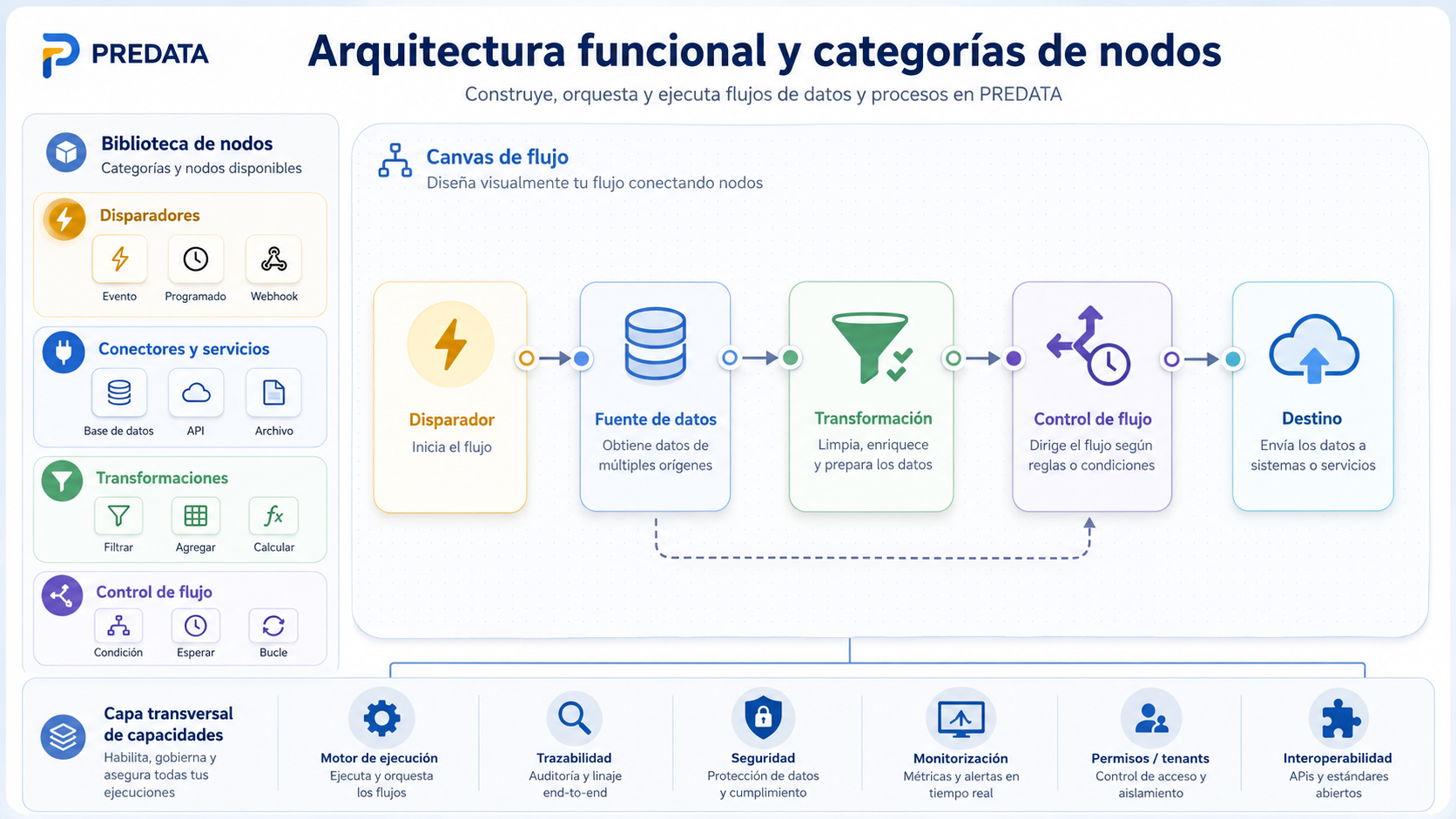
Workflows visuales: de procesos manuales a preparación automatizada
Uno de los elementos centrales de PREDATA es su enfoque basado en workflows visuales. La herramienta permite construir procesos de datos mediante un lienzo compuesto por nodos configurables, donde cada nodo representa una acción concreta dentro del flujo.
Este enfoque facilita que los procesos de preparación puedan definirse, reutilizarse, ejecutarse y supervisarse de forma más estructurada. Un workflow puede comenzar con un disparador, conectarse a una fuente de datos, aplicar transformaciones, controlar la lógica de ejecución y finalizar exportando un dataset preparado.
Las principales categorías funcionales desarrolladas son:
- Disparadores: inicio manual, programado, por evento o mediante API.
- Conectores y servicios: bases de datos, ficheros, APIs, aplicaciones cloud y sistemas externos.
- Transformaciones: limpieza, mapeo, anonimización, calidad, datos sintéticos, anomalías, agregaciones y exportación.
- Control de flujo: condiciones, ramas, esperas, reintentos, bucles controlados y ejecución de subprocesos.
Este modelo convierte procesos que tradicionalmente podían ser manuales, dispersos o poco trazables en flujos reutilizables y supervisables.
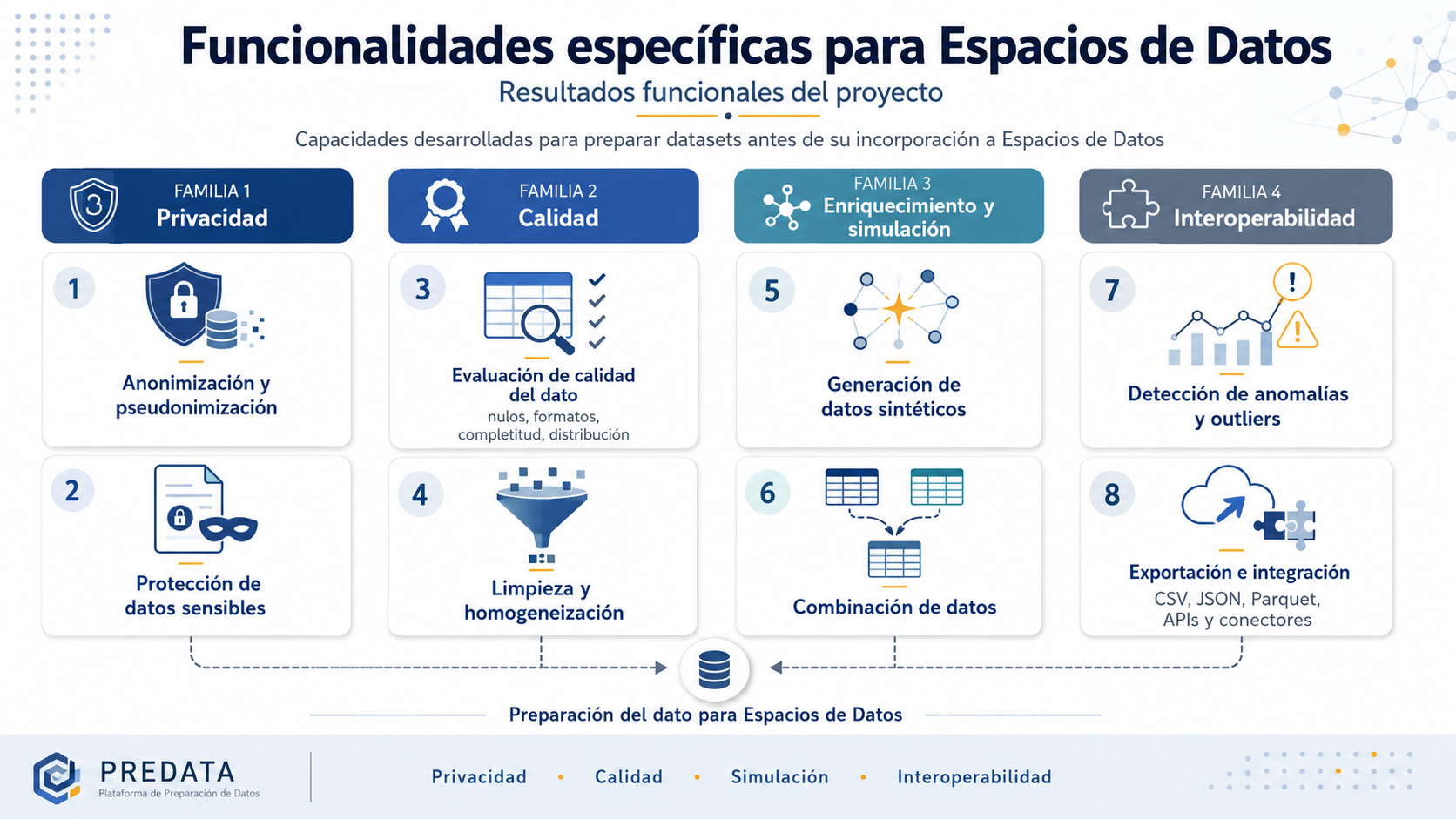
Funcionalidades específicas para Espacios de Datos
Durante el proyecto se han desarrollado funcionalidades especialmente relevantes para la preparación de datos antes de su incorporación a Espacios de Datos.
Estas capacidades responden a necesidades habituales en entornos colaborativos y federados, donde los datos deben compartirse con garantías de calidad, privacidad e interoperabilidad.
Entre las funcionalidades destacadas se incluyen:
- Anonimización y pseudonimización de datos sensibles.
- Generación de datos sintéticos para pruebas y validación.
- Evaluación de calidad del dato: nulos, formatos, completitud y distribución.
- Limpieza y homogeneización de valores.
- Combinación de datos procedentes de distintas fuentes.
- Detección de anomalías y outliers.
- Exportación a formatos estándar como CSV, JSON o Parquet.
- Preparación para integración mediante APIs y conectores.
Estas funcionalidades permiten transformar datos heterogéneos en datasets más fiables, seguros y preparados para su reutilización.
Ejemplos de casos reales
Como parte de las actividades de difusión del proyecto, se llevó a cabo un webinar en el que se presentaron los principales resultados de PREDATA y se realizó una demostración práctica de la herramienta.
Durante la sesión, se mostraron varios casos de uso representativos que permitieron visualizar el funcionamiento extremo a extremo de la solución. A través de estos ejemplos, se pudo observar cómo se parte de distintos datasets iniciales, se configuran workflows de preparación y se obtienen salidas listas para su uso posterior o integración.
Los casos de uso incluyeron la carga de datasets de ejemplo, la aplicación de operaciones de anonimización o pseudonimización, la evaluación de calidad del dato, la detección de valores problemáticos, la combinación de fuentes y la exportación en formatos estándar, así como la revisión de las ejecuciones realizadas.
Esta demostración refuerza uno de los mensajes principales del proyecto: PREDATA no se limita a definir un enfoque conceptual, sino que materializa una herramienta funcional para preparar datos de forma visual, trazable y reutilizable.
Puedes ver la grabación del webinar y la demostración práctica en el canal de difusión del proyecto. Webinar de PREDATA
Validación, documentación y difusión
Además del desarrollo funcional de la herramienta, el proyecto ha incluido una fase final orientada a la validación, las pruebas, la documentación y la difusión de resultados.
Esta fase permite comprobar el funcionamiento de PREDATA, documentar sus capacidades, facilitar su comprensión por parte de entidades interesadas y ampliar el impacto del proyecto dentro del ecosistema de Espacios de Datos.
Las acciones de difusión incluyen la publicación de contenidos en el blog corporativo, materiales divulgativos, webinars, demostraciones online y comunicaciones orientadas a compartir los resultados alcanzados con empresas, administraciones, centros tecnológicos y entidades vinculadas al ámbito de los datos.
Acceso público, validación gratuita y transferencia de resultados
Como parte del compromiso de difusión y transferencia de resultados, la información pública del proyecto estará disponible a través de la web de PREDATA y de los materiales asociados al webinar.
Además, se plantea un acceso inicial gratuito para que entidades interesadas puedan conocer y validar la herramienta en escenarios reales o pilotos acotados. Este acceso está orientado especialmente a Espacios de Datos, empresas proveedoras de datos y organizaciones que necesiten preparar datasets antes de compartirlos o reutilizarlos.
La finalidad es facilitar el acceso no discriminatorio a los resultados, promover su validación técnica, recoger feedback de potenciales usuarios y ampliar el impacto del proyecto.
Conclusión: PREDATA como habilitador para la economía del dato
PREDATA demuestra la importancia de contar con herramientas específicas para la preparación del dato en el contexto de los Espacios de Datos. La calidad, la privacidad, la trazabilidad y la interoperabilidad no aparecen al final del proceso: deben trabajarse antes de compartir o integrar los datasets.
El proyecto ha permitido desarrollar una herramienta funcional que aborda esta necesidad mediante workflows visuales, nodos configurables y capacidades orientadas a transformar datos heterogéneos en datasets preparados.
Con ello, PREDATA contribuye a facilitar la participación de organizaciones en ecosistemas de datos más seguros, confiables e interoperables, reforzando el papel de la preparación del dato como paso clave para impulsar la economía del dato.



