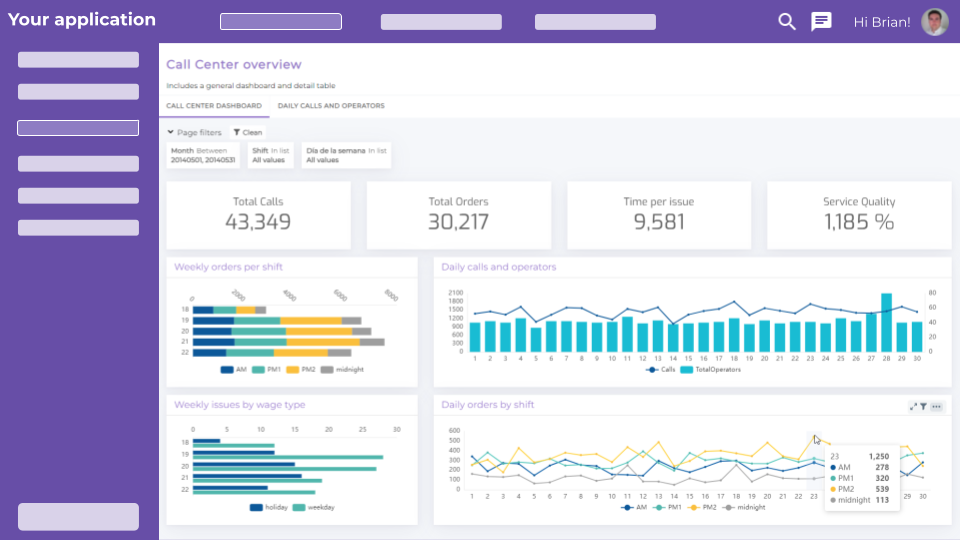
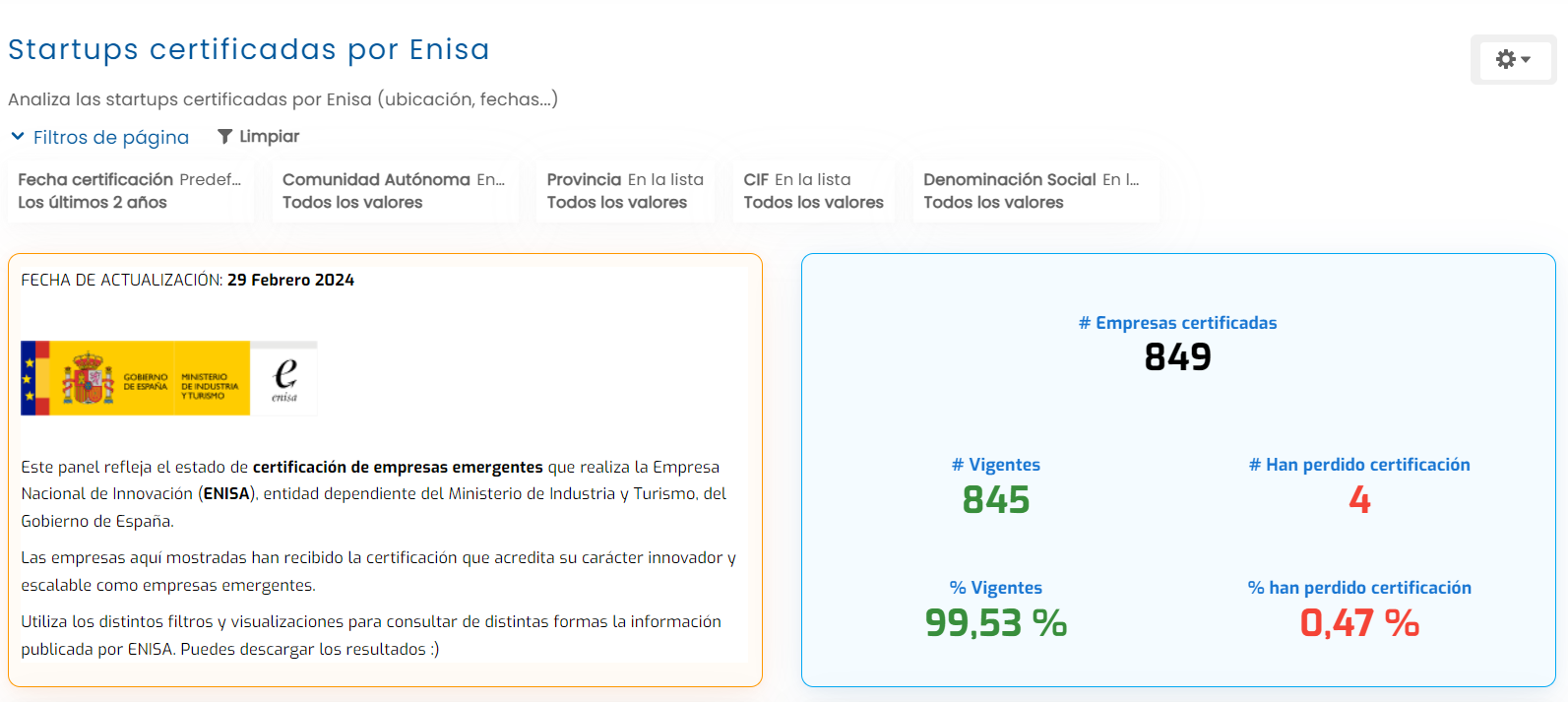
Artificial intelligence is changing the way companies interact with their data. We are no longer talking only about dashboards, reports, or traditional business intelligence views. We are talking about conversational assistants, automatic generation of data workflows or pipelines, visualizations, metric recommendations, intelligent summaries, and models capable of answering questions in natural language.

The promise is powerful: access information faster, reduce technical dependency, and enable more people across the organization to explore data without needing to master SQL, BI tools, or complex analytical models.
But there is one question many companies are overlooking: what happens if that artificial intelligence works with unreliable, poorly defined data or data without business context?
The answer matters. AI can accelerate the way we query, interpret, or visualize information, but it cannot turn a disorganized database into a reliable source for decision-making on its own. If the data is incomplete, inconsistent, duplicated, poorly governed, or lacks a common definition, AI does not remove the problem. In many cases, it amplifies it.
This is where the difference between an AI First approach and a Data First approach appears.
AI First, when misunderstood, means starting with the visible layer: the assistant, the dashboard generator, the conversational interface, or the eye-catching experience. Data First means starting with the foundation: connected sources, prepared data, defined metrics, clear permissions, traceability, governance, a semantic layer, and a secure way to deliver information to each user.
It is not about choosing between AI and data. It is about understanding the right order.
A modern analytics strategy should not only ask how to incorporate AI. It should first ask whether the data, metrics, and models that AI will work with are consistent, understandable, and governed enough to generate trust.
From AI-generated dashboards to the real problem: trust
In the previous article, we analyzed the difference between AI-generated dashboards and real analytics platforms. The main conclusion was clear: generating a visualization is not the same as having an analytics solution ready for enterprise use.
A dashboard can look correct and still be built on incorrect data. An AI-generated answer can sound convincing and still mix metrics with different definitions. An automatic summary can be useful and, at the same time, not be aligned with the permissions, filters, data models, or business rules that each customer, team, or user needs.
This nuance is especially important in B2B environments.
When analytics is used internally, an error can create confusion, waste time, or trigger discussions between departments. But when that analytics is delivered to customers, partners, franchises, distributors, or external users, the impact is greater. We are no longer talking only about operational efficiency. We are talking about customer experience, trust, retention, and product perception.
A company can create a nice-looking dashboard in a few minutes. It can also connect an AI interface that allows users to ask about sales, margin, churn, product usage, or operational performance. But if there is no shared definition for each metric behind it, no consistent logic for each segment, no proper permissions layer, and no system that explains where each data point comes from, the experience will be fragile.
The problem is not that AI generates answers. The problem is whether those answers are verifiable, consistent, and secure.
That is why the question should not only be: “can we add AI to our dashboards?” The right question is: “do we have a data foundation, models, and metrics reliable enough for AI to create value?”
What it really means to be AI First
Being AI First can make a lot of sense when understood correctly. Artificial intelligence can reduce friction, enable self-service, help non-technical users explore information, and speed up tasks that previously took longer.
In analytics, this can translate into conversational interfaces, automatic visualization generation, metric recommendations, pattern detection, natural language explanations, or assistance when building queries.
In the data preparation layer, being AI First can provide workflow or data pipeline generation, synthetic data generation, data anonymization, and many other capabilities that enrich a traditional ETL tool and take it to a higher level.
For many teams, this promise is especially attractive because it addresses a real problem: access to data is still too slow in many organizations. Business users depend on technical teams to obtain reports. Data teams receive repetitive questions. Product teams want to offer analytics inside their applications, but they do not always have the resources to build a complete experience from scratch.
AI can help in all these scenarios. It can make data querying more natural. It can lower the barrier to entry. It can turn a business question into a query, a visualization, or a summary. It can act as a simpler interface between the user and the analytics system.
The problem appears when AI First is interpreted as “AI first, architecture later”.
In that scenario, the company adds an intelligent layer on top of processes that remain manual, data that has not been prepared, metrics without an owner, undocumented data models, and permissions that are not properly defined. The result may look modern, but it remains fragile.
AI does not know on its own which metric is the official one, which data should take precedence when sources conflict, which customer can see which information, what definition of revenue the company uses, or which dimension should be applied in each case. All of that must exist beforehand in the data architecture, in the processes, in the semantic layer, and in the platform that delivers the information.
An AI First approach without a Data First foundation can create a paradox: the company gets faster answers, but not necessarily better answers.
And in analytics, speed is only valuable when it does not compromise trust.
What it really means to be Data First
Being Data First does not mean rejecting AI. It means creating the conditions for AI to be useful.
A Data First company starts by making sure that data is ready to be consumed. This means connecting sources, cleaning and transforming information, automating recurring processes, defining metrics, establishing access rules, maintaining traceability, and delivering information in a format that each user can understand.
In a BI, embedded analytics, or data portals context, Data First means that the final visualization is not an isolated piece. It is the last layer of a system that starts much earlier.
First come the data sources: CRM, ERP, product, operations, finance, marketing, support, internal databases, or external systems. Then comes data preparation: extraction, transformation, validation, cleaning, deduplication, and enrichment. After that come the data models, business rules, metric definitions, the semantic layer, permissions, user experience, and finally the delivery layer: the data visualization layer.
Only then does it make sense to add AI as an additional layer to explore, summarize, ask questions, or accelerate interaction with information.
Data First is not about building more infrastructure for the sake of it. It is about creating a reliable foundation so that any consumption layer — dashboards, portals, embedded analytics, internal reporting, or AI models — works consistently.
Put simply: AI can improve the analytics experience, but trust depends on the data, the metrics, and the context that connects them to the business.
The semantic layer: the bridge between data, BI, and AI
Within a Data First strategy, one component is becoming increasingly important: the semantic layer.
The semantic layer acts as an intermediate layer between technical data and the tools that consume it. Its role is to translate tables, columns, relationships, and data models into business-friendly and consistent concepts: metrics, dimensions, entities, hierarchies, calculation rules, and shared definitions.
In other words, the semantic layer helps concepts such as “revenue”, “active customer”, “churn”, “margin”, “MRR”, “conversion”, “product usage”, or “average ticket” have a common and reusable definition.
This is very useful for BI tools because it prevents each dashboard, team, or analyst from rebuilding metrics in their own way. But it is also especially important for AI models.
When a user asks an assistant: “which of my customers are at the highest risk of churn?” or “how has recurring revenue evolved this quarter?”, the model needs more than access to a database. It needs context. It needs to know what each metric means, what relationships exist between entities, which filters should be applied, which dimensions are relevant, and which business rules must not be ignored.
Without a semantic layer, AI can interpret data ambiguously. It can select the wrong table, use the wrong definition, mix concepts, or answer with logic that does not match how the organization works. With a well-defined semantic layer, both BI tools and AI models can operate on the same foundation of meaning.
This does not completely remove the need for validation, governance, or supervision, but it does reduce one of the main sources of risk: semantic inconsistency.
That is why, in the age of AI, the semantic layer is no longer just a BI best practice. It becomes critical infrastructure for intelligent systems to interpret data with context, consistency, and guarantees.
A Data First strategy should not be limited to storing and visualizing data. It should also define the common language the organization uses to understand that data.
AI First vs Data First: a practical comparison
The difference between AI First and Data First is not whether or not you use artificial intelligence. The difference lies in what you consider to be the foundation of the system.
In a poorly designed AI First approach, the priority is to generate answers quickly. In a Data First approach, the priority is to generate reliable answers. In the first case, the visible layer can move faster than the foundation. In the second, the foundation allows any visible layer — dashboards, portals, embedded analytics, or AI — to work consistently.
| Dimension | Misunderstood AI First | Data First |
|---|---|---|
| Starting point | AI interface | Data, models, metrics, and context |
| Priority | Generate answers quickly | Generate reliable answers |
| Main risk | Inconsistent answers, false confidence, or ambiguous interpretation | More initial work on preparation and governance |
| Relationship with metrics | AI may interpret each metric depending on the available context | Metrics are defined, documented, and reused consistently |
| Semantic layer | May not exist or may be implicit in each tool | Acts as a common language between data, BI, and AI |
| Scalability | Limited if data is not governed or prepared to grow | High if there is a solid architecture |
| Maintenance | Difficult if each output is generated in isolation | Manageable if metrics, models, permissions, and semantics are centralized |
| User experience | Attractive, but potentially fragile | Consistent, secure, and trustworthy |
| B2B fit | Risky in multi-client scenarios without permissions and governance | Suitable for reporting, data portals, and embedded analytics |
| Outcome | Fast insights, but not always actionable | More reliable and repeatable decisions |
This has direct implications for SaaS companies, ISVs, and organizations that deliver reporting to customers.
If each customer sees data under different rules, if metrics do not have a shared definition, if the semantic layer does not exist, or if permissions are not properly handled, adding AI does not solve the problem. It can make it more visible. And in some cases, harder to control.
By contrast, when a Data First foundation exists, AI can become a real advantage: it helps users query better, detect patterns, explain information, and accelerate access to insights without compromising trust.
Why this debate matters especially for SaaS companies and ISVs
For a SaaS company or an ISV (Independent Software Vendor), analytics is not just reporting. In many cases, it is part of the product itself.
Customers expect clear metrics, useful dashboards, and up-to-date data inside their usual experience. They do not want to export information, request manual reports, or depend on the support team to understand what is happening. They want self-service, clarity, and trust.
In this context, a superficial AI First approach can be dangerous. A conversational interface may look innovative, but if there is no multi-client architecture, access control, traceability, semantic layer, and shared definitions behind it, the experience can break quickly.
Imagine a SaaS company that provides performance metrics to its customers. If each customer accesses a portal with their own data, the system must guarantee that no one sees information they should not see. It must also ensure that KPIs have a consistent definition, that filters are applied correctly, and that AI-generated answers respect the same permissions model as the official dashboards.
In this kind of scenario, the problem is not only technical. It is a product and trust problem.
A Data First approach makes it possible to build analytics as a product capability. Not just as another screen, but as an integrated part of the value proposition: embedded dashboards, data portals, white-label reporting, permissions by user or customer, consistent metrics, and an experience aligned with each user’s context.
AI can come later to improve exploration, but it should not replace the foundation.
In fact, the more strategic analytics becomes inside the product, the more important it is for AI to operate on a prepared system. It is not enough for the model to answer. It must answer with the right data, the right context, the right metrics, and the right restrictions.
The problem that comes next: maintenance, changes, and scalability
Another common limitation of an AI First approach is that it often solves the initial problem better than the ongoing one.

AI can help generate a first dashboard, a first query, a first pipeline, or a first visualization. It can accelerate prototyping and reduce the time needed to reach a first version. But an enterprise analytics solution does not end when it is generated for the first time. It starts precisely there.
Then come functional changes, new business requirements, modifications to data sources, new metrics, changes in calculation logic, segmentation needs, new permission rules, security adjustments, audits, performance optimizations, and scaling scenarios.
What happens if the definition of a critical metric changes? Who updates all the dashboards, models, and answers that depend on it? What if a customer needs a new access rule? How do you ensure that this rule is applied in the same way in a dashboard, in a data portal, and in an AI-generated query? What happens if the platform goes from 100 users consuming information to 1,000, 10,000, or more?
These problems are less visible than the initial generation, but they are much more important for a company. AI can be very useful for creating, suggesting, or accelerating. But maintaining a stable, secure, governed, and scalable solution requires architecture, processes, ownership, and a platform prepared to operate over time.
In enterprise analytics, the difficulty is not only creating an answer. It is ensuring that the answer remains correct when data, business rules, users, permissions, or consumption volume change.
That is why the Data First approach is not simply a more organized way to start. It is a more robust way to maintain. When defined models, governed metrics, a semantic layer, traceability, permissions, and a delivery architecture exist, changes can be managed centrally and consistently. When everything depends on isolated generated artifacts, maintenance becomes more fragile.
A real analytics solution must be able to evolve. It must support new requirements without breaking what already exists. It must allow a metric to be changed without creating contradictory versions. It must scale to more users without compromising performance or security. And it must do all this with clear responsibilities, not as a collection of one-off generated outputs.
This is one of the major differences between “generating analytics” and “operating an analytics platform”. The first part may look fast. The second is what determines whether the system lasts.
The common mistake: confusing speed with reliability
One of the major appeals of AI is speed. It can generate answers in seconds, create visualizations quickly, and lower the barrier to entry for non-technical users.
But in enterprise analytics, speed and reliability are not the same thing.

A fast answer may be poorly contextualized. An automatically generated dashboard may use the wrong metric. A recommendation may seem reasonable, but not be aligned with business logic. And when this happens, the cost is not only technical. It is organizational and commercial.
Internally, this creates discussions about which number is correct. For customers, it creates loss of trust. In product, it creates friction. In sales, it can complicate a demo or a renewal. In operations, it can lead to wrong decisions.
The semantic layer helps reduce precisely this risk. If metrics, dimensions, hierarchies, and business rules are defined in a common layer, BI tools and AI systems do not need to interpret every query from scratch. They work on a shared framework.
This does not mean everything is automatically solved. Data still needs to be governed, models supervised, answers validated, and a secure architecture maintained. But it does mean the organization reduces the likelihood that two different tools will provide different answers to the same question.
That is why companies that want to incorporate AI into their analytics should first ask themselves: can we explain where each data point comes from, what each metric means, who defines it, and who should be able to see it?
If the answer is no, the problem is not AI. It is the foundation.
How to combine AI and Data First correctly
The right combination is not AI versus data. It is AI on top of reliable data.
The first step is to organize data sources and preparation processes. This means reducing manual tasks, automating transformations, avoiding duplicates, and ensuring that data reaches the analytics system in good condition.
The second step is to define clear data models. Relationships between entities, tables, customers, products, events, accounts, or transactions must be structured in a way that can be understood and reused by different tools.
The third step is to define metrics and ownership. Every important KPI should have a clear definition, an owner, and consistent logic. If sales, product, and operations use different definitions for the same metric, any BI or AI layer will inherit that ambiguity.
The fourth step is to build a semantic layer. This layer adds context to models and metrics, translates technical complexity into business language, and allows both BI tools and AI models to interpret data consistently. It is not only about naming metrics; it is about defining their logic, relationships, dimensions, and rules of use.
The fifth step is to apply governance, security, and permissions. This is critical when data is delivered to customers, partners, or external users. Not every user should see the same information, and not every context requires the same level of granularity.
The sixth step is to deliver analytics in the right place: internal dashboards, embedded analytics, data portals, or white-label reporting. The experience matters, but it must be supported by a solid foundation.
Only after that does it make sense to incorporate AI as an exploration, assistance, or automation layer.
The correct sequence is not “AI → data”. It is “reliable data → consistent models → semantic layer → useful analytics → AI as an accelerator”.
What an analytics platform ready for the AI era should include
An analytics platform prepared for the AI era should not be limited to displaying charts. It should help build a reliable, secure, and reusable analytical foundation.
This means solving several layers at once.
First, it must be able to connect to different data sources and help prepare information before it reaches the end user. If data requires constant manual processes, intermediate spreadsheets, or undocumented transformations, analytics will be difficult to scale.
Second, it must enable the creation of clear, reusable dashboards adapted to different user profiles. Not every user needs the same level of detail, and not everyone interprets data from the same context.
Third, it must include security and access control. In multi-client scenarios, embedded analytics, or data portals, this is not optional. It is a basic condition for delivering data to external users.
Fourth, it must facilitate consistency in metrics and models. This is where the semantic layer plays a key role, because it helps different tools and users work from the same business definition.
And fifth, it must be prepared so that AI can consume data with enough context. It is not enough to connect a model to a database. AI needs to understand what metrics mean, which relationships exist, which rules must be applied, and what access limits each user has.
A practical checklist for evaluating a modern analytics platform could include:
- Connection to multiple data sources.
- Data preparation and transformation.
- Automation of recurring processes.
- Reusable data models.
- Semantic layer for metrics, dimensions, and business context.
- Clear and reusable dashboards.
- Security by role, user, customer, or group.
- Multi-client capability.
- Embedded analytics options.
- Data portals for external users.
- White-label experience.
- Traceability and consistency of metrics.
- Scalability to grow without rebuilding the system.
- Ability to feed BI tools and AI models from a shared foundation.
- Centralized management of changes in metrics, models, permissions, and business rules.
- Operational scalability to support more users, customers, and use cases without rebuilding the architecture.
A modern platform should not be limited to visualizing data. It should help prepare it, govern it, contextualize it, deliver it, and turn it into decisions.
It should also make long-term maintenance easier. It is not enough to create dashboards or intelligent answers once. The platform must allow metrics to evolve, models to be adapted, permissions to change, new users to be added, and new functional requirements to be addressed without turning every change into a technical project from scratch.
Biuwer’s role in a Data First strategy
Biuwer fits into this debate because its value proposition is not limited to creating dashboards. Its approach is to help companies prepare and deliver reliable data to customers and teams, from data integration and preparation to consumption through dashboards, embedded analytics, and data portals.
For SaaS companies, ISVs, consulting firms, multi-client organizations, or companies with complex reporting needs, this is especially relevant. Analytics cannot depend on manual reports, ad hoc development, or solutions that do not scale. It needs a platform that combines visual experience, security, self-service, scalability, and delivery capabilities.
In that context, AI can be a value layer. But the real value starts earlier: by building a reliable, governed data foundation prepared to be consumed by the right people, in the right context.
The Data First approach connects directly with an end-to-end vision of data: sources, preparation, models, metrics, semantic layer, dashboards, embedded analytics, data portals, and decisions. Each layer adds value, but also reduces risk.
For a product team, this means being able to offer analytics inside an application without building the entire infrastructure from scratch. For a data team, it means reducing inconsistencies and making information delivery easier. For an executive team, it means making decisions with greater confidence. For end customers, it means accessing clear, secure, and understandable data.
AI does not disappear from this vision. On the contrary: it becomes more useful when it has a reliable foundation to work on.
Conclusion: AI does not replace trust
Artificial intelligence will transform the way we interact with data. But it does not change a basic reality: to make good decisions, we first need reliable data.
AI First can create eye-catching experiences. Data First creates systems that scale.
The best strategy is not to choose between them. It is to first build a solid foundation of data, models, metrics, semantic layer, security, maintenance, and analytics delivery, and then use AI to accelerate access to insights.
Because in analytics, the most important question is not whether an answer is generated quickly.
It is whether it can be trusted.
If your company is building customer reporting, embedded analytics, or data portals, Biuwer can help you deliver reliable data in a visual, secure, and scalable way.
FAQs
What does AI First mean?
AI First means prioritizing artificial intelligence as the main layer for interaction, automation, or answer generation. In analytics, this usually translates into automatically generated dashboards, natural language queries, or assistants for exploring data.
What does Data First mean?
Data First means first building a reliable data foundation: quality, governance, traceability, models, metrics, security, and preparation processes. AI can then be added as a value layer on top of that foundation.
Is AI First or Data First better?
They are not mutually exclusive approaches, but in enterprise analytics it is better to start with Data First. If data is not reliable, AI can accelerate errors, inconsistencies, and poorly grounded decisions.
What is a semantic layer in analytics?
A semantic layer is a layer that defines metrics, dimensions, relationships, and business rules so that different tools can interpret data consistently. It helps BI and AI work from the same shared context.
Why is the semantic layer important for AI?
Because AI models need context to interpret data correctly. Without a semantic layer, they can use ambiguous definitions, select incorrect metrics, or answer with logic that differs from the organization’s own logic.
Can AI create reliable dashboards?
It can help generate visualizations, queries, or summaries, but reliability depends on the quality, structure, governance, semantic context, and security of the data it works with.
How can a Data First strategy be applied in analytics?
The first step is to organize sources, prepare data, define models, establish metrics, build a semantic layer, apply permissions, ensure traceability, and deliver information through dashboards, embedded analytics, or data portals adapted to each user.