The PREDATA (Preparation and Refinement Environment for DATAspaces) project was created with the aim of developing a cloud-based tool for advanced data preparation and processing, designed to facilitate its subsequent connection and integration with Data Spaces.
Following the work carried out throughout the project, PREDATA is presented as a functional tool that enables the creation of visual workflows to transform heterogeneous data into more reliable, secure and interoperable datasets. This article summarises the main results obtained and forms part of the project’s broad dissemination activities, together with the presentation webinar, the practical demonstration of the tool and the associated public materials.

The objective is to share the knowledge generated during the project with the data ecosystem, explain the need addressed and show how PREDATA helps solve one of the key challenges involved in participating in Data Spaces: preparing data before sharing it.
The context: why Data Spaces need prepared data
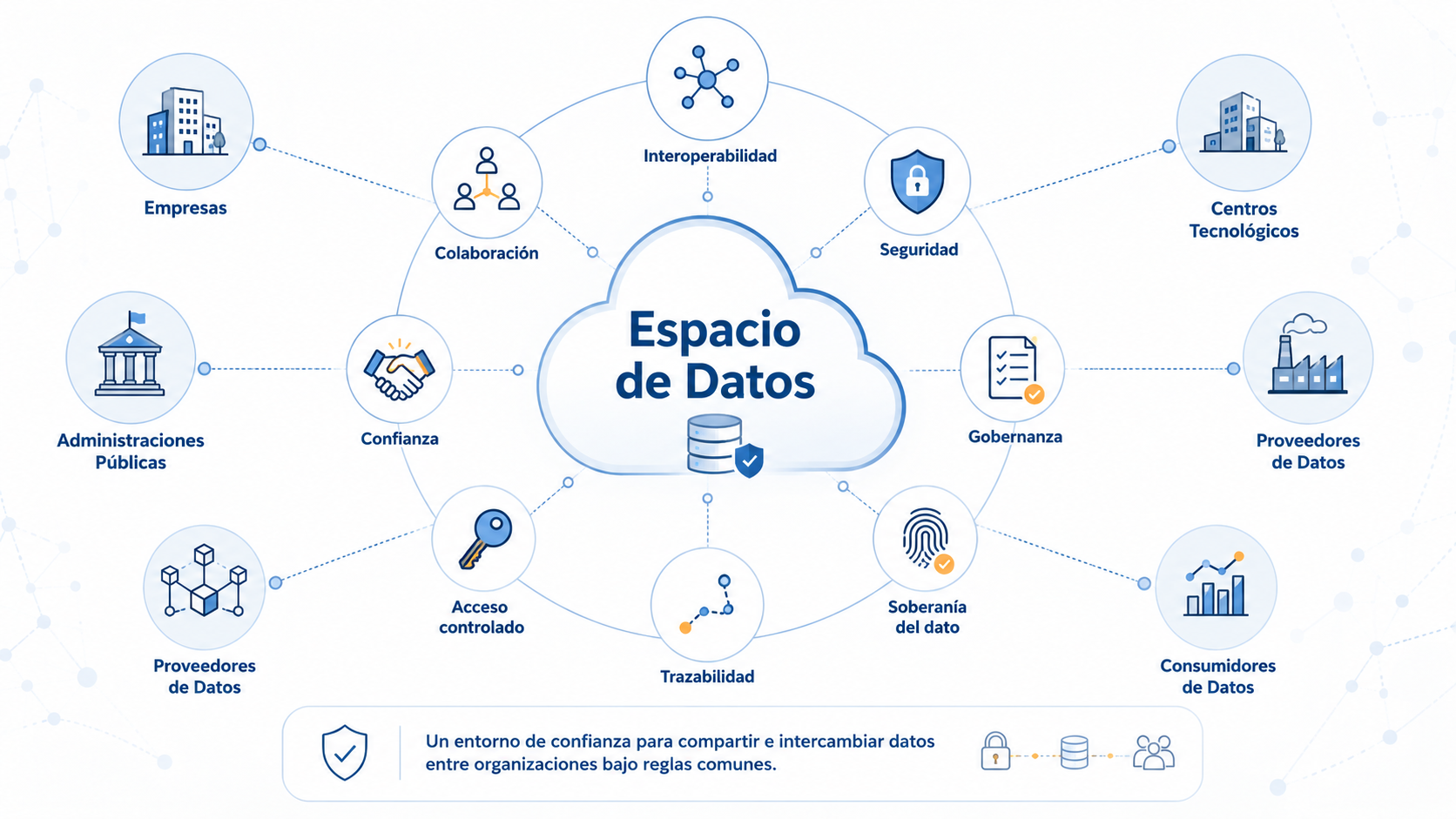
Data Spaces are trusted environments that allow different organisations to share, publish, consume or exchange data under common rules. They are not simply centralised databases, but ecosystems involving participants, technology, governance, security, traceability and access control.
For these ecosystems to work properly, simply having data is not enough. Data must meet minimum requirements in terms of quality, structure, privacy, interoperability and traceability. Without this prior preparation, reuse becomes more complex and the risk of errors, regulatory non-compliance or loss of trust between participants increases.
In this context, PREDATA has been developed as a tool focused precisely on this preliminary stage: the processing and refinement of data before it is incorporated into a Data Space.
""Having data is not enough. To share it with guarantees, it must first be prepared.
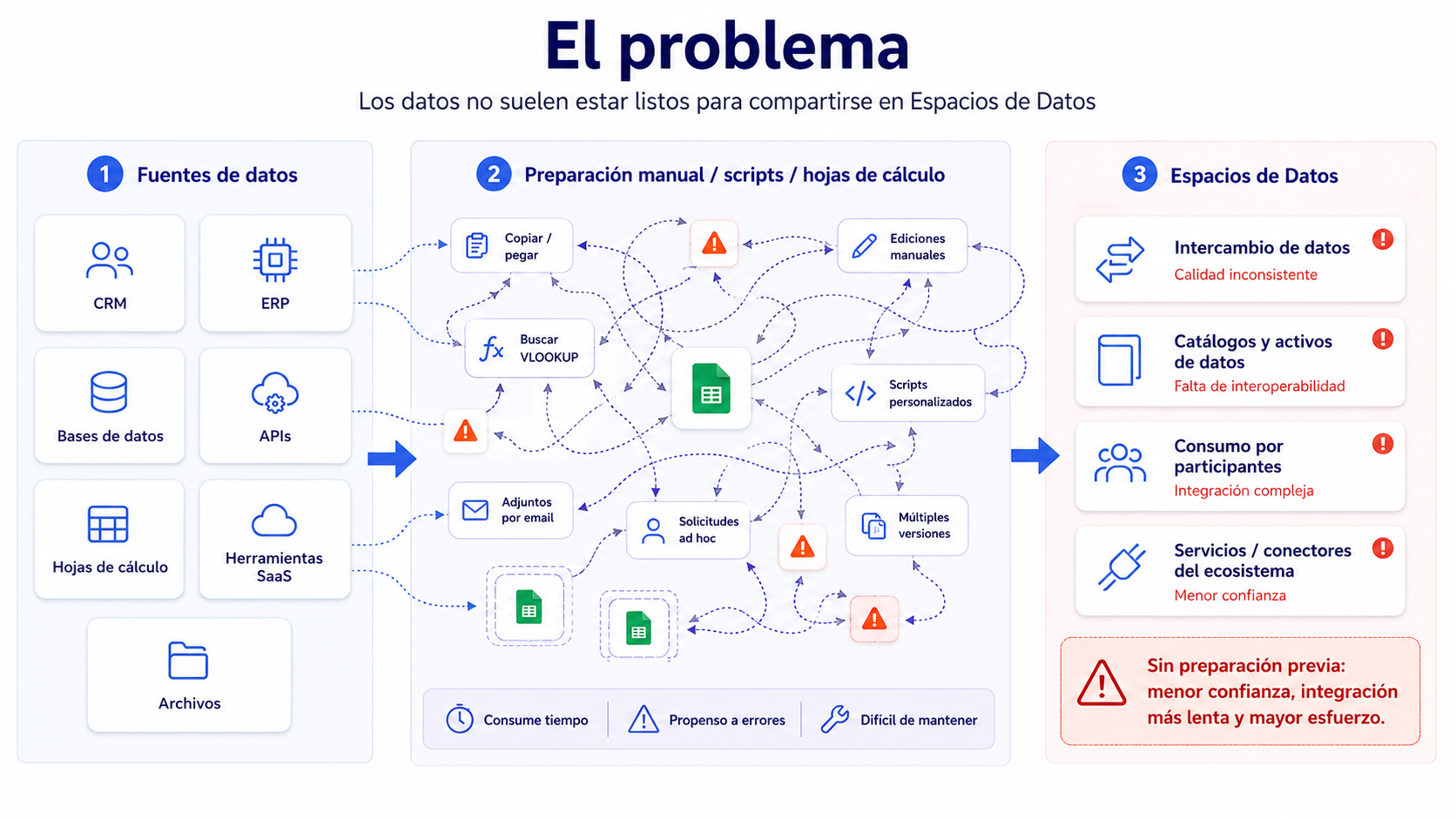
The problem addressed: fragmented, heterogeneous data that is difficult to reuse
In many organisations, data is distributed across multiple systems: internal databases, CSV or Excel files, APIs, cloud applications, IoT sensors or document repositories. In addition, this data may present different levels of quality and structure.
The most common challenges include non-standardised formats, incomplete or inconsistent values, duplicates, sensitive information, lack of traceability over the transformations applied, and difficulty exporting datasets in interoperable formats.
This problem is not only technical. It directly affects trust, privacy, data reuse and the ability of organisations to participate in collaborative ecosystems. For this reason, one of the project’s key conclusions is that prior data preparation must be addressed as a specific, automatable and traceable stage within the data lifecycle.
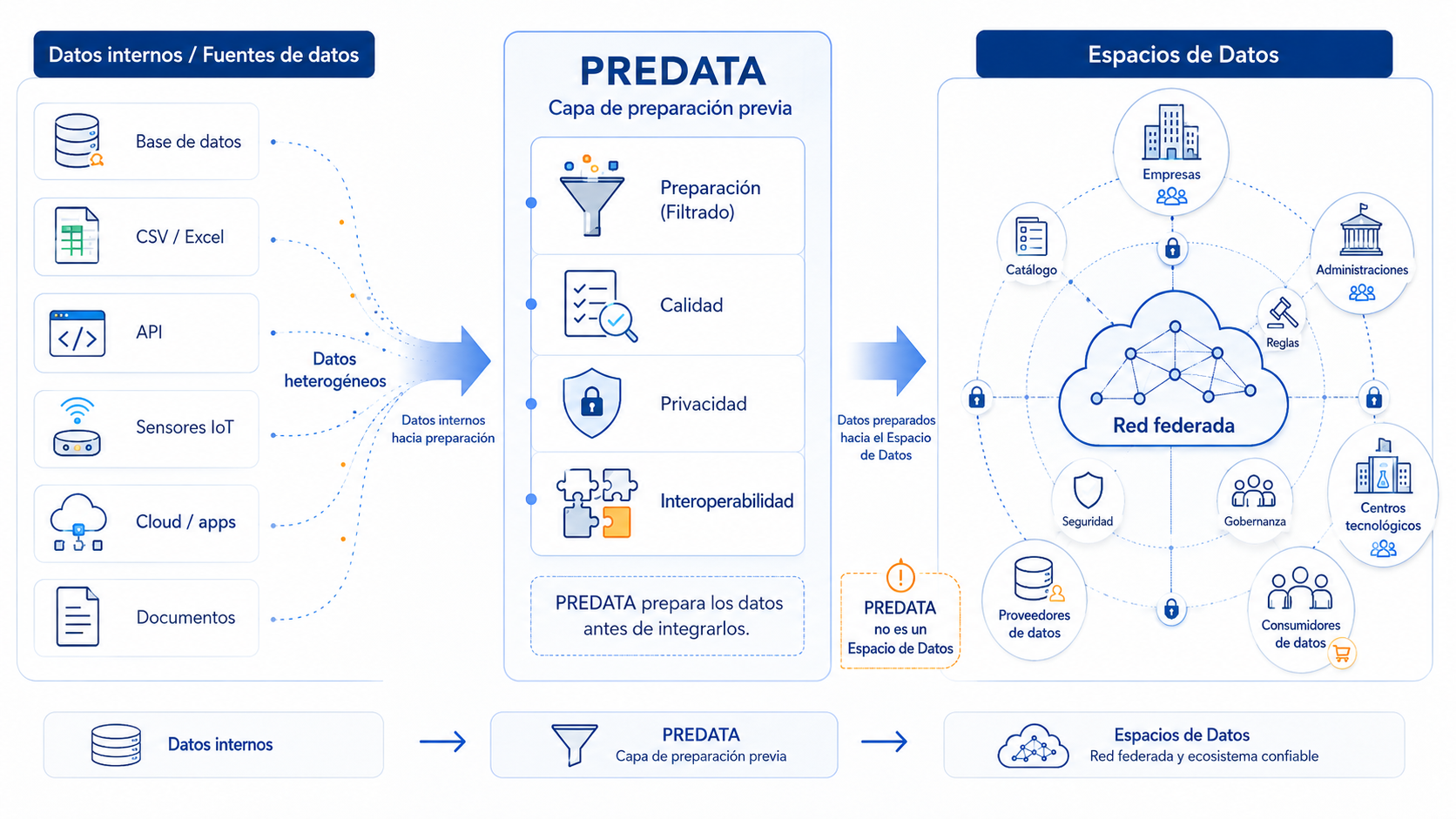
The solution developed: PREDATA as a preliminary data preparation layer
PREDATA has been developed as a preliminary data preparation layer. Its aim is not to replace a Data Space, but to help data reach these environments under better conditions of quality, security and interoperability.
The tool makes it possible to create visual data processing workflows, connect heterogeneous sources, apply transformations, validate dataset quality, protect sensitive information and export results in standard formats.
From a functional perspective, PREDATA acts as a bridge between an organisation’s internal systems and the environments where that data can later be shared, consumed or reused.
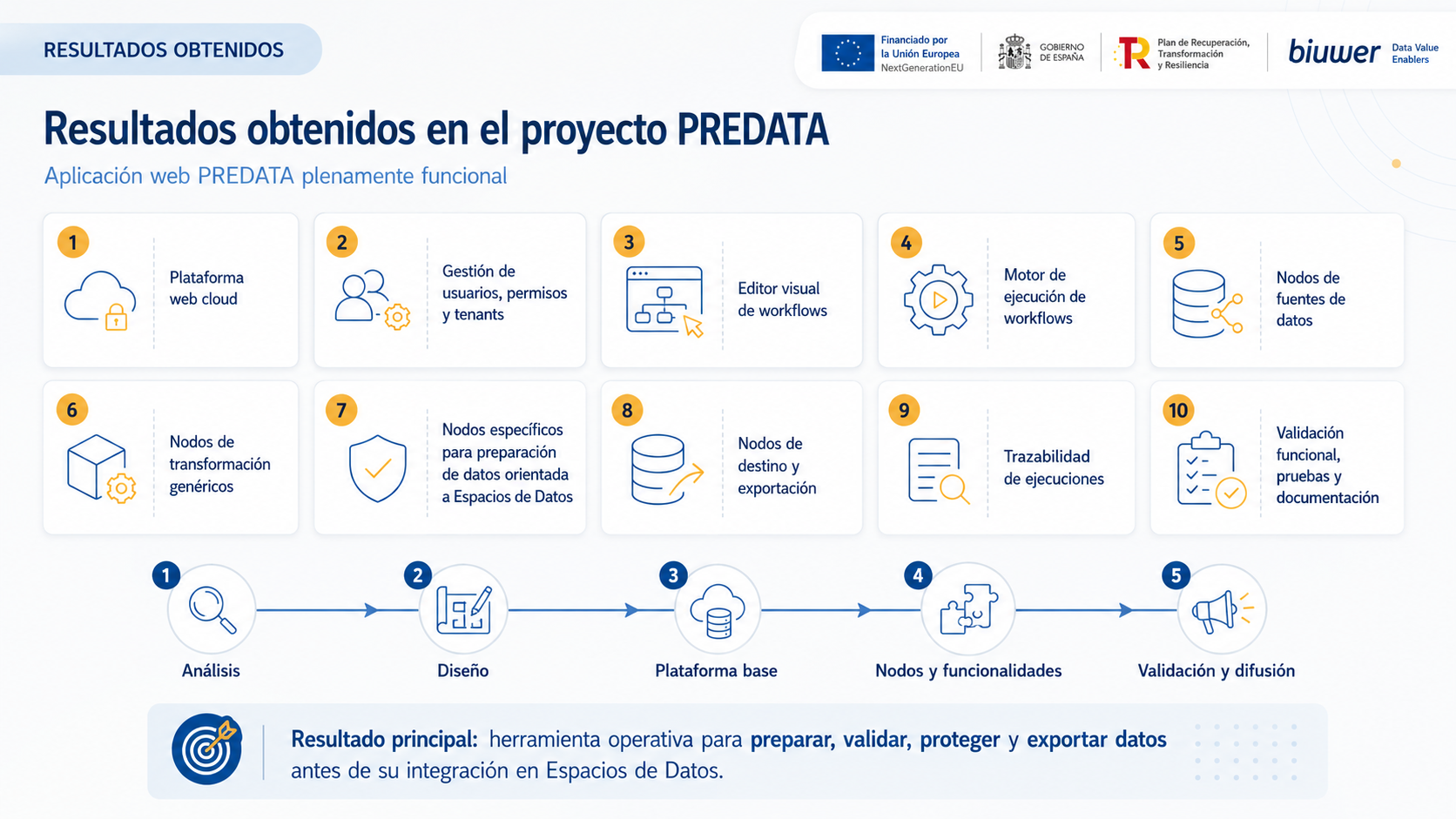
Technical results obtained
As a result of the project, a functional tool has been developed that integrates the components needed to design, execute and supervise data preparation processes through workflows.
The main results obtained include:
- Cloud-based web platform for managing data workflows.
- Management of users, permissions and tenants.
- Visual workflow editor based on configurable nodes.
- Workflow execution engine.
- Nodes for connecting to data sources.
- Generic data transformation nodes.
- Specific nodes for Data Space-oriented data preparation.
- Destination and export nodes.
- Execution traceability and audit capabilities.
- Functional validation, testing and user documentation.
The main result is an operational tool for preparing, validating, protecting and exporting data before its integration into Data Spaces.
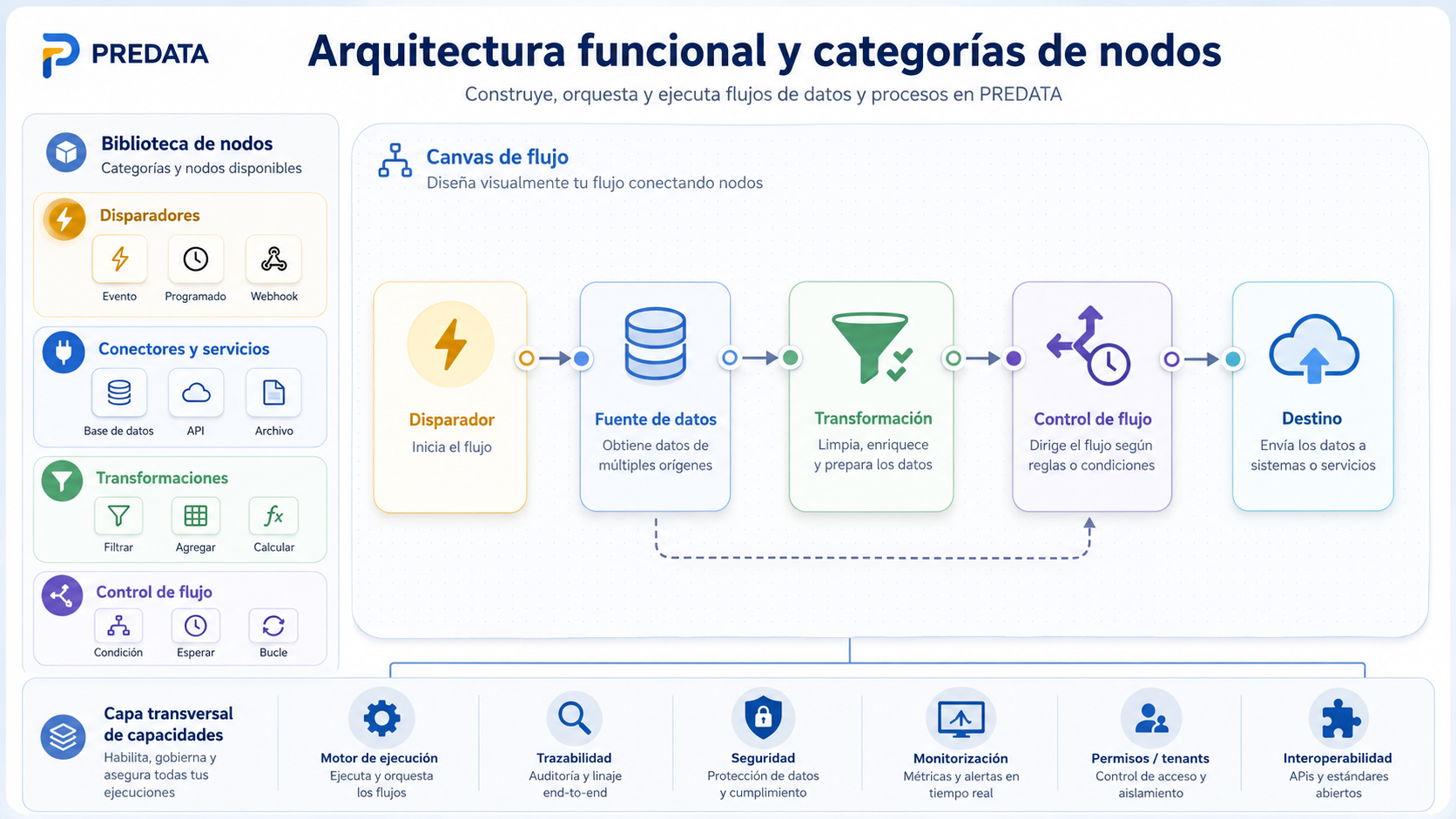
Visual workflows: from manual processes to automated preparation
One of the central elements of PREDATA is its approach based on visual workflows. The tool enables data processes to be built using a canvas made up of configurable nodes, where each node represents a specific action within the flow.
This approach makes it easier for preparation processes to be defined, reused, executed and supervised in a more structured way. A workflow can start with a trigger, connect to a data source, apply transformations, control the execution logic and end by exporting a prepared dataset.
The main functional categories developed are:
- Triggers: manual, scheduled, event-based or API-based start.
- Connectors and services: databases, files, APIs, cloud applications and external systems.
- Transformations: cleaning, mapping, anonymisation, quality, synthetic data, anomalies, aggregations and export.
- Flow control: conditions, branches, waits, retries, controlled loops and subprocess execution.
This model turns processes that traditionally could be manual, scattered or difficult to trace into reusable and monitorable flows.
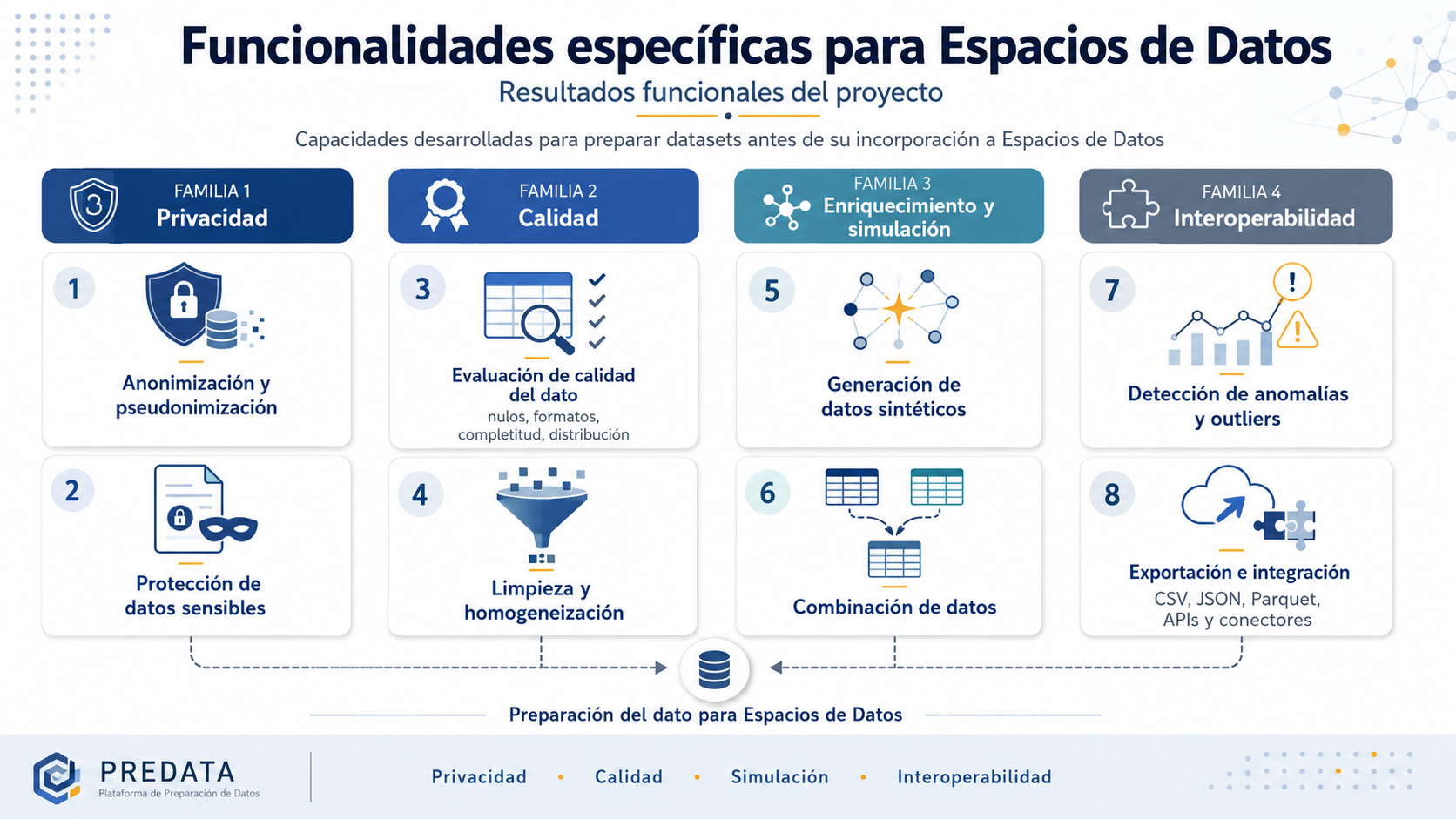
Specific functionalities for Data Spaces
During the project, functionalities of particular relevance for preparing data before its incorporation into Data Spaces have been developed.
These capabilities respond to common needs in collaborative and federated environments, where data must be shared with guarantees of quality, privacy and interoperability.
The highlighted functionalities include:
- Anonymisation and pseudonymisation of sensitive data.
- Generation of synthetic data for testing and validation.
- Data quality assessment: nulls, formats, completeness and distribution.
- Cleaning and homogenisation of values.
- Combination of data from different sources.
- Detection of anomalies and outliers.
- Export to standard formats such as CSV, JSON or Parquet.
- Preparation for integration through APIs and connectors.
These functionalities make it possible to transform heterogeneous data into more reliable, secure datasets prepared for reuse.
Examples of real use cases
As part of the project’s dissemination activities, a webinar was held in which the main results of PREDATA were presented and a practical demonstration of the tool was carried out.
During the session, several representative use cases were shown, making it possible to visualise the end-to-end operation of the solution. Through these examples, it was possible to observe how different initial datasets are taken, preparation workflows are configured and outputs are obtained ready for later use or integration.
The use cases included loading sample datasets, applying anonymisation or pseudonymisation operations, assessing data quality, detecting problematic values, combining sources and exporting in standard formats, as well as reviewing the executions performed.
This demonstration reinforces one of the project’s main messages: PREDATA is not limited to defining a conceptual approach, but materialises a functional tool for preparing data in a visual, traceable and reusable way.
You can watch the webinar recording and the practical demonstration on the project’s dissemination channel. PREDATA Webinar
Validation, documentation and dissemination
In addition to the functional development of the tool, the project has included a final phase focused on validation, testing, documentation and dissemination of results.
This phase makes it possible to verify the operation of PREDATA, document its capabilities, facilitate understanding by interested organisations and broaden the project’s impact within the Data Spaces ecosystem.
Dissemination actions include the publication of content on the corporate blog, dissemination materials, webinars, online demonstrations and communications aimed at sharing the results achieved with companies, public administrations, technology centres and entities linked to the data ecosystem.
Public access, free validation and transfer of results
As part of the commitment to dissemination and transfer of results, public information about the project will be available through the PREDATA website and the materials associated with the webinar.
In addition, initial free access is planned so that interested organisations can learn about and validate the tool in real-world scenarios or limited pilots. This access is especially aimed at Data Spaces, data-providing companies and organisations that need to prepare datasets before sharing or reusing them.
The purpose is to facilitate non-discriminatory access to the results, promote their technical validation, collect feedback from potential users and broaden the project’s impact.
Conclusion: PREDATA as an enabler for the data economy
PREDATA demonstrates the importance of having specific tools for data preparation in the context of Data Spaces. Quality, privacy, traceability and interoperability do not appear at the end of the process: they must be worked on before datasets are shared or integrated.
The project has made it possible to develop a functional tool that addresses this need through visual workflows, configurable nodes and capabilities designed to transform heterogeneous data into prepared datasets.
In doing so, PREDATA helps organisations participate in more secure, trusted and interoperable data ecosystems, reinforcing the role of data preparation as a key step in driving the data economy.



